

Slonik
A Node.js PostgreSQL client with runtime and build time type safety, and co...
README
Slonik




A battle-tested Node.js PostgreSQL client with strict types, detailed logging and assertions.
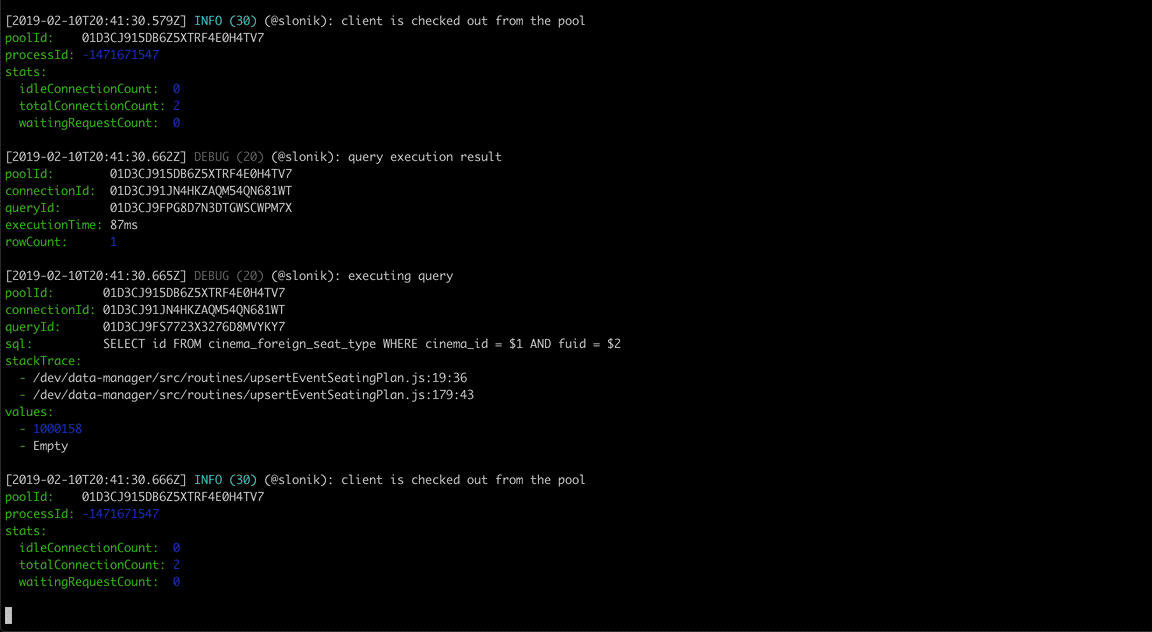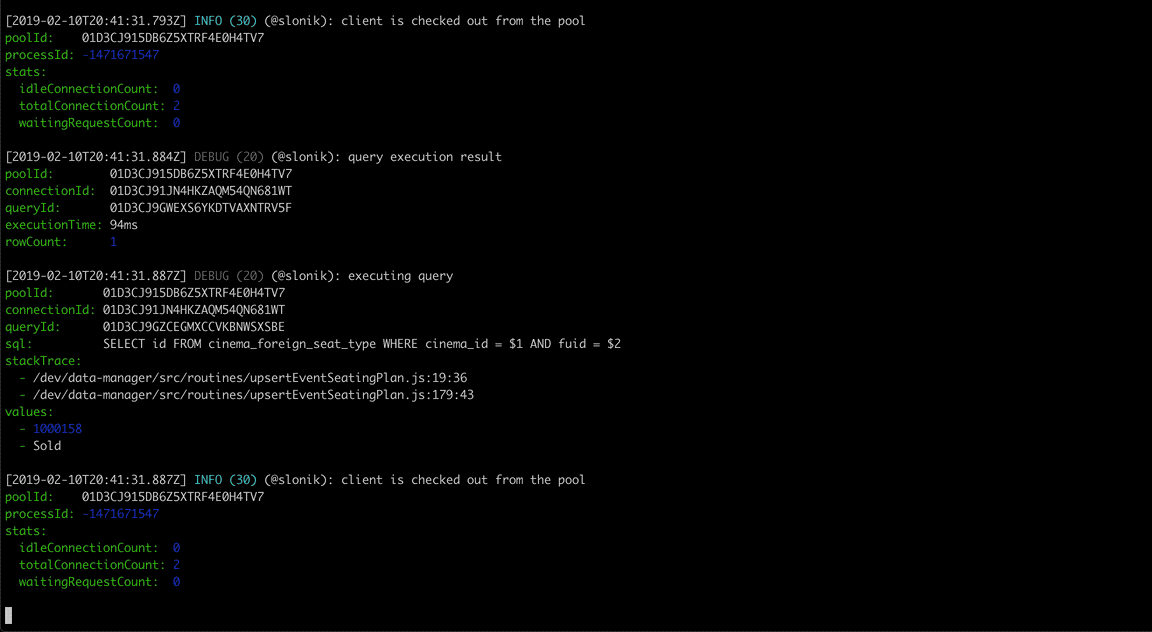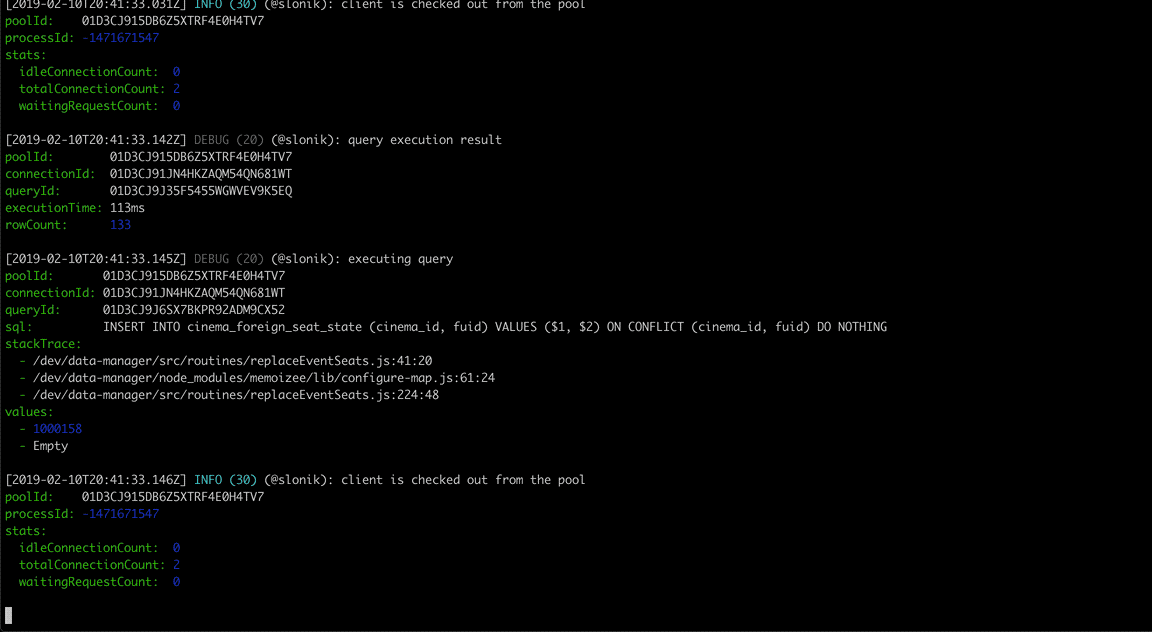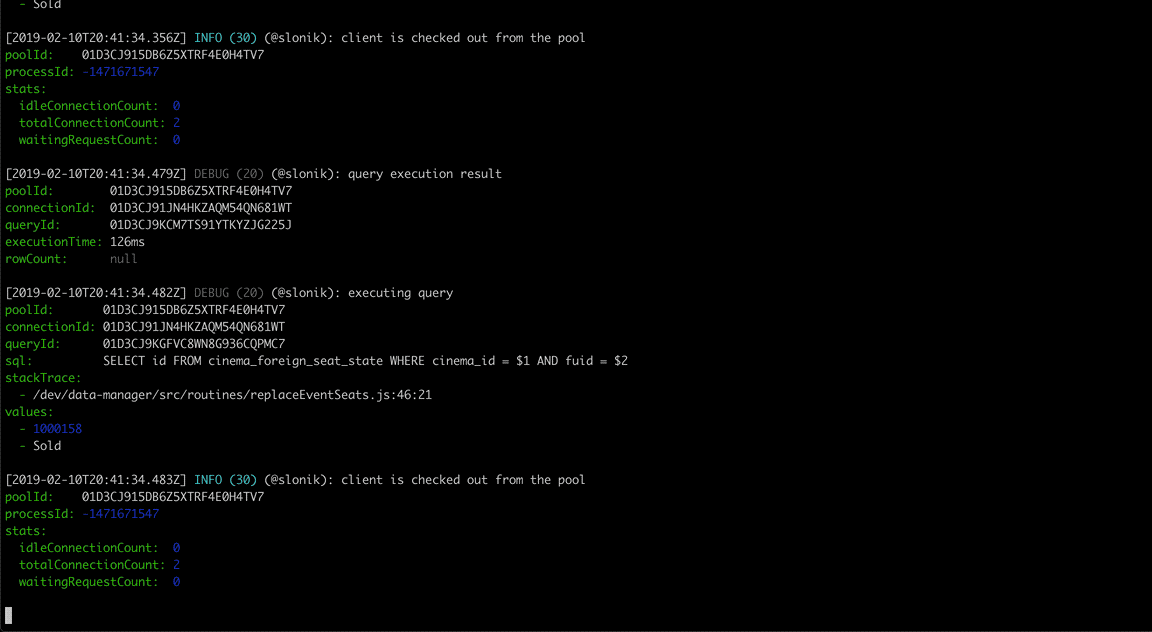
(The above GIF shows Slonik producing query logs. Slonik produces logs using Roarr. Logs include stack trace of the actual query invocation location and values used to execute the query.)
Sponsors
If you value my work and want to see Slonik and many other of my Open-Source projects to be continuously improved, then please consider becoming a patron:

Principles
Promotes writing raw SQL.
Discourages ad-hoc dynamic generation of SQL.
Read: Stop using Knex.js
Note: Using this project does not require TypeScript. It is a regular ES6 module. Ignore the type definitions used in the documentation if you do not use a type system.
Features
Detailed logging.
Contents
[pg vs slonik](#user-content-slonik-how-are-they-different-pg-vs-slonik)
[pg-promise vs slonik](#user-content-slonik-how-are-they-different-pg-promise-vs-slonik)
[postgres vs slonik](#user-content-slonik-how-are-they-different-postgres-vs-slonik)
[Example use of sql.type](#user-content-slonik-runtime-validation-example-use-of-sql-type)
[sql tag](#user-content-slonik-sql-tag)
[Typing sql tag](#user-content-slonik-sql-tag-typing-sql-tag)
[Nesting sql](#user-content-slonik-value-placeholders-nesting-sql)
[sql.array](#user-content-slonik-query-building-sql-array)
[sql.binary](#user-content-slonik-query-building-sql-binary)
[sql.date](#user-content-slonik-query-building-sql-date)
[sql.fragment](#user-content-slonik-query-building-sql-fragment)
[sql.identifier](#user-content-slonik-query-building-sql-identifier)
[sql.interval](#user-content-slonik-query-building-sql-interval)
[sql.join](#user-content-slonik-query-building-sql-join)
[sql.json](#user-content-slonik-query-building-sql-json)
[sql.jsonb](#user-content-slonik-query-building-sql-jsonb)
[sql.literalValue](#user-content-slonik-query-building-sql-literalvalue)
[sql.timestamp](#user-content-slonik-query-building-sql-timestamp)
[sql.unnest](#user-content-slonik-query-building-sql-unnest)
[sql.unsafe](#user-content-slonik-query-building-sql-unsafe)
[any](#user-content-slonik-query-methods-any)
[anyFirst](#user-content-slonik-query-methods-anyfirst)
[exists](#user-content-slonik-query-methods-exists)
[copyFromBinary](#user-content-slonik-query-methods-copyfrombinary)
[many](#user-content-slonik-query-methods-many)
[manyFirst](#user-content-slonik-query-methods-manyfirst)
[maybeOne](#user-content-slonik-query-methods-maybeone)
[maybeOneFirst](#user-content-slonik-query-methods-maybeonefirst)
[one](#user-content-slonik-query-methods-one)
[oneFirst](#user-content-slonik-query-methods-onefirst)
[query](#user-content-slonik-query-methods-query)
[stream](#user-content-slonik-query-methods-stream)
[transaction](#user-content-slonik-query-methods-transaction)
[parseDsn](#user-content-slonik-utilities-parsedsn)
[stringifyDsn](#user-content-slonik-utilities-stringifydsn)
[Original node-postgres error](#user-content-slonik-error-handling-original-node-postgres-error)
[Handling BackendTerminatedError](#user-content-slonik-error-handling-handling-backendterminatederror)
[Handling CheckIntegrityConstraintViolationError](#user-content-slonik-error-handling-handling-checkintegrityconstraintviolationerror)
[Handling ConnectionError](#user-content-slonik-error-handling-handling-connectionerror)
[Handling DataIntegrityError](#user-content-slonik-error-handling-handling-dataintegrityerror)
[Handling ForeignKeyIntegrityConstraintViolationError](#user-content-slonik-error-handling-handling-foreignkeyintegrityconstraintviolationerror)
[Handling NotFoundError](#user-content-slonik-error-handling-handling-notfounderror)
[Handling NotNullIntegrityConstraintViolationError](#user-content-slonik-error-handling-handling-notnullintegrityconstraintviolationerror)
[Handling StatementCancelledError](#user-content-slonik-error-handling-handling-statementcancellederror)
[Handling StatementTimeoutError](#user-content-slonik-error-handling-handling-statementtimeouterror)
[Handling UniqueIntegrityConstraintViolationError](#user-content-slonik-error-handling-handling-uniqueintegrityconstraintviolationerror)
[Handling TupleMovedToAnotherPartitionError](#user-content-slonik-error-handling-handling-tuplemovedtoanotherpartitionerror)
About Slonik
Battle-Tested
Slonik began as a collection of utilities designed for working with [node-postgres](https://github.com/brianc/node-postgres). It continues to use node-postgres driver as it provides a robust foundation for interacting with PostgreSQL. However, what once was a collection of utilities has since grown into a framework that abstracts repeating code patterns, protects against unsafe connection handling and value interpolation, and provides a rich debugging experience.
Slonik has been battle-tested with large data volumes and queries ranging from simple CRUD operations to data-warehousing needs.
Origin of the name

The name of the elephant depicted in the official PostgreSQL logo is Slonik. The name itself is derived from the Russian word for "little elephant".
Repeating code patterns and type safety
Among the primary reasons for developing Slonik, was the motivation to reduce the repeating code patterns and add a level of type safety. This is primarily achieved through the methods such as one, many, etc. But what is the issue? It is best illustrated with an example.
Suppose the requirement is to write a method that retrieves a resource ID given values defining (what we assume to be) a unique constraint. If we did not have the aforementioned helper methods available, then it would need to be written as:
- ```ts
- import {
- sql,
- type DatabaseConnection
- } from 'slonik';
- type DatabaseRecordIdType = number;
- const getFooIdByBar = async (connection: DatabaseConnection, bar: string): Promise<DatabaseRecordIdType> => {
- const fooResult = await connection.query(sql.typeAlias('id')`
- SELECT id
- FROM foo
- WHERE bar = ${bar}
- `);
- if (fooResult.rowCount === 0) {
- throw new Error('Resource not found.');
- }
- if (fooResult.rowCount > 1) {
- throw new Error('Data integrity constraint violation.');
- }
- return fooResult[0].id;
- };
- ```
oneFirst method abstracts all of the above logic into:
- ```ts
- const getFooIdByBar = (connection: DatabaseConnection, bar: string): Promise<DatabaseRecordIdType> => {
- return connection.oneFirst(sql.typeAlias('id')`
- SELECT id
- FROM foo
- WHERE bar = ${bar}
- `);
- };
- ```
oneFirst throws:
NotFoundError if query returns no rows
DataIntegrityError if query returns multiple rows
DataIntegrityError if query returns multiple columns
In the absence of helper methods, the overhead of repeating code becomes particularly visible when writing routines where multiple queries depend on the proceeding query results. Using methods with inbuilt assertions ensures that in case of an error, the error points to the source of the problem. In contrast, unless assertions for all possible outcomes are typed out as in the previous example, the unexpected result of the query will be fed to the next operation. If you are lucky, the next operation will simply break; if you are unlucky, you are risking data corruption and hard-to-locate bugs.
Furthermore, using methods that guarantee the shape of the results allows us to leverage static type checking and catch some of the errors even before executing the code, e.g.
- ```ts
- const fooId = await connection.many(sql.typeAlias('id')`
- SELECT id
- FROM foo
- WHERE bar = ${bar}
- `);
- await connection.query(sql.typeAlias('void')`
- DELETE FROM baz
- WHERE foo_id = ${fooId}
- `);
- ```
Static type check of the above example will produce a warning as the fooId is guaranteed to be an array and binding of the last query is expecting a primitive value.
Protecting against unsafe connection handling
Slonik only allows to check out a connection for the duration of the promise routine supplied to the pool#connect() method.
The primary reason for implementing _only_ this connection pooling method is because the alternative is inherently unsafe, e.g.
- ```ts
- // This is not valid Slonik API
- const main = async () => {
- const connection = await pool.connect();
- await connection.query(sql.typeAlias('foo')`SELECT foo()`);
- await connection.release();
- };
- ```
In this example, if SELECT foo() produces an error, then connection is never released, i.e. the connection hangs indefinitely.
A fix to the above is to ensure that connection#release() is always called, i.e.
- ```ts
- // This is not valid Slonik API
- const main = async () => {
- const connection = await pool.connect();
- let lastExecutionResult;
- try {
- lastExecutionResult = await connection.query(sql.typeAlias('foo')`SELECT foo()`);
- } finally {
- await connection.release();
- }
- return lastExecutionResult;
- };
- ```
Slonik abstracts the latter pattern into pool#connect() method.
- ```ts
- const main = () => {
- return pool.connect((connection) => {
- return connection.query(sql.typeAlias('foo')`SELECT foo()`);
- });
- };
- ```
Using this pattern, we guarantee that connection is always released as soon as the connect() routine resolves or is rejected.
Protecting against unsafe transaction handling
Just like in the unsafe connection handling example, Slonik only allows to create a transaction for the duration of the promise routine supplied to theconnection#transaction() method.
- ```ts
- connection.transaction(async (transactionConnection) => {
- await transactionConnection.query(sql.typeAlias('void')`INSERT INTO foo (bar) VALUES ('baz')`);
- await transactionConnection.query(sql.typeAlias('void')`INSERT INTO qux (quux) VALUES ('quuz')`);
- });
- ```
This pattern ensures that the transaction is either committed or aborted the moment the promise is either resolved or rejected.
Protecting against unsafe value interpolation
SQL injections are one of the most well known attack vectors. Some of the biggest data leaks were the consequence of improper user-input handling. In general, SQL injections are easily preventable by using parameterization and by restricting database permissions, e.g.
- ```ts
- // This is not valid Slonik API
- connection.query('SELECT $1', [
- userInput
- ]);
- ```
In this example, the query text (SELECT $1) and parameters (userInput) are passed separately to the PostgreSQL server where the parameters are safely substituted into the query. This is a safe way to execute a query using user-input.
The vulnerabilities appear when developers cut corners or when they do not know about parameterization, i.e. there is a risk that someone will instead write:
- ```ts
- // This is not valid Slonik API
- connection.query('SELECT \'' + userInput + '\'');
- ```
As evident by the history of the data leaks, this happens more often than anyone would like to admit. This security vulnerability is especially a significant risk in Node.js community, where a predominant number of developers are coming from frontend and have not had training working with RDBMSes. Therefore, one of the key selling points of Slonik is that it adds multiple layers of protection to prevent unsafe handling of user input.
To begin with, Slonik does not allow running plain-text queries.
- ```ts
- // This is not valid Slonik API
- connection.query('SELECT 1');
- ```
The above invocation would produce an error:
TypeError: Query must be constructed using sql tagged template literal.
This means that the only way to run a query is by constructing it using [sql tagged template literal](https://github.com/gajus/slonik#slonik-value-placeholders-tagged-template-literals), e.g.
- ```ts
- connection.query(sql.unsafe`SELECT 1`);
- ```
To add a parameter to the query, user must use template literal placeholders, e.g.
- ```ts
- connection.query(sql.unsafe`SELECT ${userInput}`);
- ```
Slonik takes over from here and constructs a query with value bindings, and sends the resulting query text and parameters to PostgreSQL. There is no other way of passing parameters to the query – this adds a strong layer of protection against accidental unsafe user input handling due to limited knowledge of the SQL client API.
As Slonik restricts user's ability to generate and execute dynamic SQL, it provides helper functions used to generate fragments of the query and the corresponding value bindings, e.g. [sql.identifier](#user-content-sqlidentifier), [sql.join](#user-content-sqljoin) and [sql.unnest](#user-content-sqlunnest). These methods generate tokens that the query executor interprets to construct a safe query, e.g.
- ```ts
- connection.query(sql.unsafe`
- SELECT ${sql.identifier(['foo', 'a'])}
- FROM (
- VALUES
- (
- ${sql.join(
- [
- sql.join(['a1', 'b1', 'c1'], sql.fragment`, `),
- sql.join(['a2', 'b2', 'c2'], sql.fragment`, `)
- ],
- sql.fragment`), (`
- )}
- )
- ) foo(a, b, c)
- WHERE foo.b IN (${sql.join(['c1', 'a2'], sql.fragment`, `)})
- `);
- ```
This (contrived) example generates a query equivalent to:
- ```sql
- SELECT "foo"."a"
- FROM (
- VALUES
- ($1, $2, $3),
- ($4, $5, $6)
- ) foo(a, b, c)
- WHERE foo.b IN ($7, $8)
- ```
This query is executed with the parameters provided by the user.
To sum up, Slonik is designed to prevent accidental creation of queries vulnerable to SQL injections.
Documentation
Usage
Connection URI
Slonik client is configured using a custom connection URI (DSN).
- ```tson
- postgresql://[user[:password]@][host[:port]][/database name][?name=value[&...]]
- ```
Supported parameters:
| |Name|Meaning|Default| |
|---|
| |---|---|---| |
| |`application_name`|[`application_name`](https://www.postgresql.org/docs/current/libpq-connect.html#LIBPQ-CONNECT-APPLICATION-NAME)|| |
| |`sslmode`|[`sslmode`](https://www.postgresql.org/docs/current/libpq-connect.html#LIBPQ-CONNECT-SSLMODE) |
Note that unless listed above, other libpq parameters are not supported.
Examples of valid DSNs:
- ```text
- postgresql://
- postgresql://localhost
- postgresql://localhost:5432
- postgresql://localhost/foo
- postgresql://foo@localhost
- postgresql://foo:bar@localhost
- postgresql://foo@localhost/bar?application_name=baz
- ```
Other configurations are available through the [clientConfiguration parameter](https://github.com/gajus/slonik#api).
Create connection
Use createPool to create a connection pool, e.g.
- ```ts
- import {
- createPool,
- } from 'slonik';
- const pool = await createPool('postgres://');
- ```
Instance of Slonik connection pool can be then used to create a new connection, e.g.
- ```ts
- pool.connect(async (connection) => {
- await connection.query(sql.typeAlias('id')`SELECT 1 AS id`);
- });
- ```
The connection will be kept alive until the promise resolves (the result of the method supplied to connect()).
Refer to query method documentation to learn about the connection methods.
If you do not require having a persistent connection to the same backend, then you can directly use pool to run queries, e.g.
- ```ts
- pool.query(sql.typeAlias('id')`SELECT 1 AS id`);
- ```
Beware that in the latter example, the connection picked to execute the query is a random connection from the connection pool, i.e. using the latter method (without explicit connect()) does not guarantee that multiple queries will refer to the same backend.
End connection pool
Use pool.end() to end idle connections and prevent creation of new connections.
The result of pool.end() is a promise that is resolved when all connections are ended.
- ```ts
- import {
- createPool,
- sql,
- } from 'slonik';
- const pool = await createPool('postgres://');
- const main = async () => {
- await pool.query(sql.typeAlias('id')`
- SELECT 1 AS id
- `);
- await pool.end();
- };
- main();
- ```
Note: pool.end() does not terminate active connections/ transactions.
Describing the current state of the connection pool
Use pool.getPoolState() to find out if pool is alive and how many connections are active and idle, and how many clients are waiting for a connection.
- ```ts
- import {
- createPool,
- sql,
- } from 'slonik';
- const pool = await createPool('postgres://');
- const main = async () => {
- pool.getPoolState();
- // {
- // activeConnectionCount: 0,
- // ended: false,
- // idleConnectionCount: 0,
- // waitingClientCount: 0,
- // }
- await pool.connect(() => {
- pool.getPoolState();
- // {
- // activeConnectionCount: 1,
- // ended: false,
- // idleConnectionCount: 0,
- // waitingClientCount: 0,
- // }
- });
- pool.getPoolState();
- // {
- // activeConnectionCount: 0,
- // ended: false,
- // idleConnectionCount: 1,
- // waitingClientCount: 0,
- // }
- await pool.end();
- pool.getPoolState();
- // {
- // activeConnectionCount: 0,
- // ended: true,
- // idleConnectionCount: 0,
- // waitingClientCount: 0,
- // }
- };
- main();
- ```
Note: pool.end() does not terminate active connections/ transactions.
API
- ```ts
- /**
- * @param connectionUri PostgreSQL [Connection URI](https://www.postgresql.org/docs/current/libpq-connect.html#LIBPQ-CONNSTRING).
- */
- createPool(
- connectionUri: string,
- clientConfiguration: ClientConfiguration
- ): DatabasePool;
- /**
- * @property captureStackTrace Dictates whether to capture stack trace before executing query. Middlewares access stack trace through query execution context. (Default: false)
- * @property connectionRetryLimit Number of times to retry establishing a new connection. (Default: 3)
- * @property connectionTimeout Timeout (in milliseconds) after which an error is raised if connection cannot be established. (Default: 5000)
- * @property idleInTransactionSessionTimeout Timeout (in milliseconds) after which idle clients are closed. Use 'DISABLE_TIMEOUT' constant to disable the timeout. (Default: 60000)
- * @property idleTimeout Timeout (in milliseconds) after which idle clients are closed. Use 'DISABLE_TIMEOUT' constant to disable the timeout. (Default: 5000)
- * @property interceptors An array of [Slonik interceptors](https://github.com/gajus/slonik#slonik-interceptors).
- * @property maximumPoolSize Do not allow more than this many connections. Use 'DISABLE_TIMEOUT' constant to disable the timeout. (Default: 10)
- * @property PgPool Override the underlying PostgreSQL Pool constructor.
- * @property queryRetryLimit Number of times a query failing with Transaction Rollback class error, that doesn't belong to a transaction, is retried. (Default: 5)
- * @property ssl [tls.connect options](https://nodejs.org/api/tls.html#tlsconnectoptions-callback)
- * @property statementTimeout Timeout (in milliseconds) after which database is instructed to abort the query. Use 'DISABLE_TIMEOUT' constant to disable the timeout. (Default: 60000)
- * @property transactionRetryLimit Number of times a transaction failing with Transaction Rollback class error is retried. (Default: 5)
- * @property typeParsers An array of [Slonik type parsers](https://github.com/gajus/slonik#slonik-type-parsers).
- */
- type ClientConfiguration = {
- captureStackTrace?: boolean,
- connectionRetryLimit?: number,
- connectionTimeout?: number | 'DISABLE_TIMEOUT',
- idleInTransactionSessionTimeout?: number | 'DISABLE_TIMEOUT',
- idleTimeout?: number | 'DISABLE_TIMEOUT',
- interceptors?: Interceptor[],
- maximumPoolSize?: number,
- PgPool?: new (poolConfig: PoolConfig) => PgPool,
- queryRetryLimit?: number,
- ssl?: Parameters<tls.connect>[0],
- statementTimeout?: number | 'DISABLE_TIMEOUT',
- transactionRetryLimit?: number,
- typeParsers?: TypeParser[],
- };
- ```
Example:
- ```ts
- import {
- createPool
- } from 'slonik';
- const pool = await createPool('postgres://');
- await pool.query(sql.typeAlias('id')`SELECT 1 AS id`);
- ```
Default configuration
Default interceptors
None.
Check out [slonik-interceptor-preset](https://github.com/gajus/slonik-interceptor-preset) for an opinionated collection of interceptors.
Default type parsers
These type parsers are enabled by default:
| |Type | |Implementation| |
|---|---|
| |---|---| | |
| |`date`|Produces | |
| |`int8`|Produces | |
| |`interval`|Produces | |
| |`numeric`|Produces | |
| |`timestamp`|Produces | |
| |`timestamptz`|Produces |
To disable the default type parsers, pass an empty array, e.g.
- ```ts
- createPool('postgres://', {
- typeParsers: []
- });
- ```
You can create default type parser collection using createTypeParserPreset, e.g.
- ```ts
- import {
- createTypeParserPreset
- } from 'slonik';
- createPool('postgres://', {
- typeParsers: [
- ...createTypeParserPreset()
- ]
- });
- ```
Default timeouts
There are 4 types of configurable timeouts:
| |Configuration|Description|Default| |
|---|
| |---|---|---| |
| |`connectionTimeout`|Timeout |
| |`idleInTransactionSessionTimeout`|Timeout |
| |`idleTimeout`|Timeout |
| |`statementTimeout`|Timeout |
Slonik sets aggressive timeouts by default. These timeouts are designed to provide safe interface to the database. These timeouts might not work for all programs. If your program has long running statements, consider adjusting timeouts just for those statements instead of changing the defaults.
Known limitations of using pg-native with Slonik
notice logs are not captured in notices query result property (notice event is never fired on connection instance).
cannot combine multiple commands into a single statement (pg-native limitation #88)
does not support streams.
Checking out a client from the connection pool
Slonik only allows to check out a connection for the duration of the promise routine supplied to the pool#connect() method.
- ```ts
- import {
- createPool,
- } from 'slonik';
- const pool = await createPool('postgres://localhost');
- const result = await pool.connect(async (connection) => {
- await connection.query(sql.typeAlias('id')`SELECT 1 AS id`);
- await connection.query(sql.typeAlias('id')`SELECT 2 AS id`);
- return 'foo';
- });
- result;
- // 'foo'
- ```
Connection is released back to the pool after the promise produced by the function supplied to connect() method is either resolved or rejected.
Mocking Slonik
Slonik provides a way to mock queries against the database.
Use createMockPool to create a mock connection.
Use createMockQueryResult to create a mock query result.
- ```ts
- import {
- createMockPool,
- createMockQueryResult,
- } from 'slonik';
- type OverridesType =
- query: (sql: string, values: PrimitiveValueExpression[],) => Promise<QueryResult<QueryResultRow>>,
- };
- createMockPool(overrides: OverridesType): DatabasePool;
- createMockQueryResult(rows: QueryResultRow[]): QueryResult<QueryResultRow>;
- ```
Example:
- ```ts
- import {
- createMockPool,
- createMockQueryResult,
- } from 'slonik';
- const pool = createMockPool({
- query: async () => {
- return createMockQueryResult([
- {
- foo: 'bar',
- },
- ]);
- },
- });
- await pool.connect(async (connection) => {
- const results = await connection.query(sql.typeAlias('foo')`
- SELECT ${'foo'} AS foo
- `);
- });
- ```
How are they different?
pg vs slonik[pg](https://github.com/brianc/node-postgres) is built intentionally to provide unopinionated, minimal abstraction and encourages use of other modules to implement convenience methods.
Slonik is built on top of pg and it provides convenience methods for building queries and querying data.
pg-promise vs slonikAs the name suggests, [pg-promise](https://github.com/vitaly-t/pg-promise) was originally built to enable use of pg module with promises (at the time, pg only supported Continuation Passing Style (CPS), i.e. callbacks). Since then pg-promise added features for connection/ transaction handling, a powerful query-formatting engine and a declarative approach to handling query results.
The primary difference between Slonik and pg-promise:
Slonik does not allow to execute raw text queries. Slonik queries can only be constructed using [sql tagged template literals](#user-content-slonik-value-placeholders-tagged-template-literals). This design protects against unsafe value interpolation.
Slonik implements interceptor API (middleware). Middlewares allow to modify connection handling, override queries and modify the query results. Example Slonik interceptors include field name transformation, query normalization and query benchmarking.
Note: Author of pg-promise has objected to the above claims. I have removed a difference that was clearly wrong. I maintain that the above two differences remain valid differences: even thoughpg-promise might have substitute functionality for variable interpolation and interceptors, it implements them in a way that does not provide the same benefits that Slonik provides, namely: guaranteed security and support for extending library functionality using multiple plugins.
Other differences are primarily in how the equivalent features are implemented, e.g.
| |`pg-promise`|Slonik| |
|---|
| |---|---| |
| |[Custom |
| |[formatting |
| |[Query |
| |[Tasks](https://github.com/vitaly-t/pg-promise#tasks).|Use |
| |Configurable |
| |Events.|Use |
When weighting which abstraction to use, it would be unfair not to consider that pg-promise is a mature project with dozens of contributors. Meanwhile, Slonik is a young project (started in March 2017) that until recently was developed without active community input. However, if you do support the unique features that Slonik adds, the opinionated API design, and are not afraid of adopting a technology in its young days, then I warmly invite you to adopt Slonik and become a contributor to what I intend to make the standard PostgreSQL client in the Node.js community.
postgres vs slonik[postgres](https://github.com/porsager/postgres) recently gained in popularity due to its performance benefits when compared to pg. In terms of API, it has a pretty bare-bones API that heavily relies on using ES6 tagged templates and abstracts away many concepts of connection pool handling. While postgres API might be preferred by some, projects that already use pg may have difficulty migrating.
However, by using postgres-bridge (postgres/pg compatibility layer), you can benefit from postgres performance improvements while still using Slonik API:
- ```ts
- import postgres from 'postgres';
- import { createPostgresBridge } from 'postgres-bridge';
- import { createPool } from 'slonik';
- const PostgresBridge = createPostgresBridge(postgres);
- const pool = createPool('postgres://', {
- PgPool: PostgresBridge,
- });
- ```
Type parsers
Type parsers describe how to parse PostgreSQL types.
- ```ts
- type TypeParser = {
- name: string,
- parse: (value: string) => *
- };
- ```
Example:
- ```ts
- {
- name: 'int8',
- parse: (value) => {
- return parseInt(value, 10);
- }
- }
- ```
Note: Unlike [pg-types](https://github.com/brianc/node-pg-types) that uses OIDs to identify types, Slonik identifies types using their names.
Use this query to find type names:
- ```sql
- SELECT typname
- FROM pg_type
- ORDER BY typname ASC
- ```
Type parsers are configured using [typeParsers client configuration](#user-content-slonik-usage-api).
Read: Default type parsers.
Built-in type parsers
| |Type | |Implementation|Factory |
|---|---|
| |---|---|---| | |
| |`date`|Produces | |`createDateTypeParser`| |
| |`int8`|Produces | |`createBigintTypeParser`| |
| |`interval`|Produces | |`createIntervalTypeParser`| |
| |`numeric`|Produces | |`createNumericTypeParser`| |
| |`timestamp`|Produces | |`createTimestampTypeParser`| |
| |`timestamptz`|Produces | |`createTimestampWithTimeZoneTypeParser`| |
Built-in type parsers can be created using the exported factory functions, e.g.
- ```ts
- import {
- createTimestampTypeParser
- } from 'slonik';
- createTimestampTypeParser();
- // {
- // name: 'timestamp',
- // parse: (value) => {
- // return value === null ? value : Date.parse(value + ' UTC');
- // }
- // }
- ```
Interceptors
Functionality can be added to Slonik client by adding interceptors (middleware).
Interceptors are configured using client configuration, e.g.
- ```ts
- import {
- createPool
- } from 'slonik';
- const interceptors = [];
- const connection = await createPool('postgres://', {
- interceptors
- });
- ```
Interceptors are executed in the order they are added.
Read: Default interceptors.
Interceptor methods
Interceptor is an object that implements methods that can change the behaviour of the database client at different stages of the connection life-cycle
- ```ts
- type Interceptor = {
- afterPoolConnection?: (
- connectionContext: ConnectionContext,
- connection: DatabasePoolConnection
- ) => MaybePromise<null>,
- afterQueryExecution?: (
- queryContext: QueryContext,
- query: Query,
- result: QueryResult<QueryResultRow>
- ) => MaybePromise<QueryResult<QueryResultRow>>,
- beforePoolConnection?: (
- connectionContext: ConnectionContext
- ) => MaybePromise<?DatabasePool>,
- beforePoolConnectionRelease?: (
- connectionContext: ConnectionContext,
- connection: DatabasePoolConnection
- ) => MaybePromise<null>,
- beforeQueryExecution?: (
- queryContext: QueryContext,
- query: Query
- ) => MaybePromise<QueryResult<QueryResultRow>> | MaybePromise<null>,
- beforeQueryResult?: (
- queryContext: QueryContext,
- query: Query,
- result: QueryResult<QueryResultRow>
- ) => MaybePromise<null>,
- beforeTransformQuery?: (
- queryContext: QueryContext,
- query: Query
- ) => Promise<null>,
- queryExecutionError?: (
- queryContext: QueryContext,
- query: Query,
- error: SlonikError
- ) => MaybePromise<null>,
- transformQuery?: (
- queryContext: QueryContext,
- query: Query
- ) => Query,
- transformRow?: (
- queryContext: QueryContext,
- query: Query,
- row: QueryResultRow,
- fields: Field[],
- ) => QueryResultRow
- };
- ```
afterPoolConnectionExecuted after a connection is acquired from the connection pool (or a new connection is created), e.g.
- ```ts
- const pool = await createPool('postgres://');
- // Interceptor is executed here. ↓
- pool.connect();
- ```
afterQueryExecutionExecuted after query has been executed and before rows were transformed using transformRow.
Note: When query is executed using stream, then afterQuery is called with empty result set.
beforeQueryExecutionThis function can optionally return a direct result of the query which will cause the actual query never to be executed.
beforeQueryResultExecuted just before the result is returned to the client.
Use this method to capture the result that will be returned to the client.
beforeTransformQueryExecuted before transformQuery. Use this interceptor to capture the original query (e.g. for logging purposes).
beforePoolConnectionExecuted before connection is created.
This function can optionally return a pool to another database, causing a connection to be made to the new pool.
beforePoolConnectionReleaseExecuted before connection is released back to the connection pool, e.g.
- ```ts
- const pool = await createPool('postgres://');
- pool.connect(async () => {
- await 1;
- // Interceptor is executed here. ↓
- });
- ```
queryExecutionErrorExecuted if query execution produces an error.
Use queryExecutionError to log and/ or re-throw another error.
transformQueryExecuted before beforeQueryExecution.
Transforms query.
transformRowExecuted for each row.
Transforms row.
Use transformRow to modify the query result.
Community interceptors
| |Name|Description| |
|---|
| |---|---| |
| |[`slonik-interceptor-field-name-transformation`](https://github.com/gajus/slonik-interceptor-field-name-transformation)|Transforms |
| |[`slonik-interceptor-query-benchmarking`](https://github.com/gajus/slonik-interceptor-query-benchmarking)|Benchmarks |
| |[`slonik-interceptor-query-cache`](https://github.com/gajus/slonik-interceptor-query-cache)|Caches |
| |[`slonik-interceptor-query-logging`](https://github.com/gajus/slonik-interceptor-query-logging)|Logs |
| |[`slonik-interceptor-query-normalisation`](https://github.com/gajus/slonik-interceptor-query-normalisation)|Normalises |
Check out [slonik-interceptor-preset](https://github.com/gajus/slonik-interceptor-preset) for an opinionated collection of interceptors.
Recipes
Inserting large number of rows
Use [sql.unnest](#user-content-sqlunnest) to create a set of rows using unnest. Using the unnest approach requires only 1 variable per every column; values for each column are passed as an array, e.g.
- ```ts
- await connection.query(sql.unsafe`
- INSERT INTO foo (bar, baz, qux)
- SELECT *
- FROM ${sql.unnest(
- [
- [1, 2, 3],
- [4, 5, 6]
- ],
- [
- 'int4',
- 'int4',
- 'int4'
- ]
- )}
- `);
- ```
Produces:
- ```ts
- {
- sql: 'INSERT INTO foo (bar, baz, qux) SELECT * FROM unnest($1::int4[], $2::int4[], $3::int4[])',
- values: [
- [
- 1,
- 4
- ],
- [
- 2,
- 5
- ],
- [
- 3,
- 6
- ]
- ]
- }
- ```
Inserting data this way ensures that the query is stable and reduces the amount of time it takes to parse the query.
Routing queries to different connections
A typical load balancing requirement is to route all "logical" read-only queries to a read-only instance. This requirement can be implemented in 2 ways:
1. Create two instances of Slonik (read-write and read-only) and pass them around the application as needed.
1. Use beforePoolConnection middleware to assign query to a connection pool based on the query itself.
First option is preferable as it is the most explicit. However, it also has the most overhead to implement.
On the other hand, beforePoolConnection makes it easy to route based on conventions, but carries a greater risk of accidentally routing queries with side-effects to a read-only instance.
The first option is self-explanatory to implement, but this recipe demonstrates my convention for using beforePoolConnection to route queries.
Note: How you determine which queries are safe to route to a read-only instance is outside of scope for this documentation.
Note: beforePoolConnection only works for connections initiated by a query, i.e. pool#query and not pool#connect().
Note: pool#transaction triggers beforePoolConnection but has no query.
Note: This particular implementation does not handle [SELECT INTO](https://www.postgresql.org/docs/current/sql-selectinto.html).
- ```ts
- const readOnlyPool = await createPool('postgres://read-only');
- const pool = await createPool('postgres://main', {
- interceptors: [
- {
- beforePoolConnection: (connectionContext) => {
- if (!connectionContext.query?.sql.trim().startsWith('SELECT ')) {
- // Returning null falls back to using the DatabasePool from which the query originates.
- return null;
- }
- // This is a convention for the edge-cases where a SELECT query includes a volatile function.
- // Adding a @volatile comment anywhere into the query bypasses the read-only route, e.g.
- // sql.unsafe`
- // # @volatile
- // SELECT write_log()
- // `
- if (connectionContext.query?.sql.includes('@volatile')) {
- return null;
- }
- // Returning an instance of DatabasePool will attempt to run the query using the other connection pool.
- // Note that all other interceptors of the pool that the query originated from are short-circuited.
- return readOnlyPool;
- }
- }
- ]
- });
- // This query will use `postgres://read-only` connection.
- pool.query(sql.typeAlias('id')`SELECT 1 AS id`);
- // This query will use `postgres://main` connection.
- pool.query(sql.typeAlias('id')`UPDATE 1 AS id`);
- ```
Building Utility Statements
Parameter symbols only work in optimizable SQL commands (SELECT, INSERT, UPDATE, DELETE, and certain commands containing one of these). In other statement types (generically called utility statements, e.g. ALTER, CREATE, DROP and SET), you must insert values textually even if they are just data values.
In the context of Slonik, if you are building utility statements you must use query building methods that interpolate values directly into queries:
[sql.identifier](#user-content-slonik-query-building-sql-identifier) – for identifiers.
[sql.literalValue](#user-content-slonik-query-building-sql-literalvalue) – for values.
Example:
- ```ts
- await connection.query(sql.typeAlias('void')`
- CREATE USER ${sql.identifier(['foo'])}
- WITH PASSWORD ${sql.literalValue('bar')}
- `);
- ```
Runtime validation
Slonik integrates zod to provide runtime query result validation and static type inference.
Validating queries requires to:
1. Define a Zod object and passing it tosql.type tagged template (see below)
1. Add a result parser interceptor
Motivation
Build-time type safety guarantees that your application will work as expected at the time of the build (assuming that the types are correct in the first place).
The problem is that once you deploy the application, the database schema might change independently of the codebase. This drift may result in your application behaving in unpredictable and potentially dangerous ways, e.g., imagine if table product changed price from numeric to text. Without runtime validation, this would cause a cascade of problems and potential database corruption. Even worse, without runtime checks, this could go unnoticed for a long time.
In contrast, by using runtime checks, you can ensure that the contract between your codebase and the database is always respected. If there is a breaking change, the application fails with a loud error that is easy to debug.
By using zod, we get the best of both worlds: type safety and runtime checks.
sql.typeLet's assume that you have a PostgreSQL table person:
- ```sql
- CREATE TABLE "public"."person" (
- "id" integer GENERATED ALWAYS AS IDENTITY,
- "name" text NOT NULL,
- PRIMARY KEY ("id")
- );
- ```
and you want to retrieve all persons in the database, along with their id and name:
- ```ts
- connection.any(sql.unsafe`
- SELECT id, name
- FROM person
- `);
- ```
With your knowledge of the database schema, define a zod object:
- ```ts
- const personObject = z.object({
- id: z.number(),
- name: z.string(),
- });
- ```
Update your query to use sql.type tag and pass personObject:
- ```ts
- const personQuery = sql.type(personObject)`
- SELECT id, name
- FROM person
- `;
- ```
Finally, query the database using typed sql tagged template:
- ```ts
- const persons = await connection.any(personQuery);
- ```
With this information, Slonik guarantees that every member of persons is an object that has properties id and name, which are a non-null number and a non-null string respectively.
Performance penalty
In the context of the network overhead, validation accounts for a tiny amount of the total execution time.
Just to give an idea, in our sample of data, it takes sub 0.1ms to validate 1 row, 3ms to validate 1,000 and 25ms to validate 100,000 rows.
Unknown keys
Slonik disallows unknown keys, i.e. query that returns {foo: 'bar', baz: 'qux'} with z.object({foo: z.string()}) schema will produce SchemaValidationError error.
Handling schema validation errors
If query produces a row that does not satisfy zod object, then SchemaValidationError error is thrown.
SchemaValidationError includes properties that describe the query and validation errors:
sql – SQL of the query that produced unexpected row.
row – row data that did not satisfy the schema.
issues – array of unmet expectations.
Whenever this error occurs, the same information is also included in the logs.
In most cases, you shouldn't attempt to handle these errors at individual query level – allow to propagate to the top of the application and fix the issue when you become aware of it.
However, in cases such as dealing with unstructured data, it might be useful to handle these errors at a query level, e.g.
- ```ts
- import {
- SchemaValidationError
- } from 'slonik';
- try {
- } catch (error) {
- if (error extends SchemaValidationError) {
- // Handle scheme validation error
- }
- }
- ```
Inferring types
You can infer the TypeScript type of the query result. There are couple of ways of doing it:
- ```ts
- // Infer using z.infer
- // https://github.com/colinhacks/zod#type-inference
- type Person = z.infer<typeof personObject>;
- // from sql tagged template `parser` property
- type Person = z.infer<
- personQuery.parser
- >;
- ```
Transforming results
Using zod transform you can refine the result shape and its type, e.g.
- ```ts
- const coordinatesType = z.string().transform((subject) => {
- const [
- x,
- y,
- ] = subject.split(',');
- return {
- x: Number(x),
- y: Number(y),
- };
- });
- const zodObject = z.object({
- foo: coordinatesType,
- });
- const query = sql.type(zodObject)`SELECT '1,2' as foo`;
- const result = await pool.one(query);
- expectTypeOf(result).toMatchTypeOf<{foo: {x: number, y: number, }, }>();
- t.deepEqual(result, {
- foo: {
- x: 1,
- y: 2,
- },
- });
- ```
Result parser interceptor
Slonik works without the interceptor, but it doesn't validate the query results. To validate results, you must implement an interceptor that parses the results.
For context, when Zod parsing was first introduced to Slonik, it was enabled for all queries by default. However, I eventually realized that the baked-in implementation is not
