指标告警最容易出现两种极端:要么阈值太松,真正出问题没人知道;要么阈值太紧,每天一堆告警把大家吵麻。一次数据看板事故让我印象很深。某个订单转化率在半小时内从 18% 掉到 9%,业务群里没人收到告警,因为阈值写的是“低于 5%”。后来复盘发现,这个阈值来自很久以前的兜底配置,和当前业务基线已经没有关系。
指标告警不是给数字随便画一条红线。它要回答:这个指标正常时是什么范围,异常时会怎样变化,谁需要知道,多久内必须处理,误报和漏报哪个成本更高。指标告警先定阈值,说的是先把业务边界和响应动作说清楚,再配置工具。
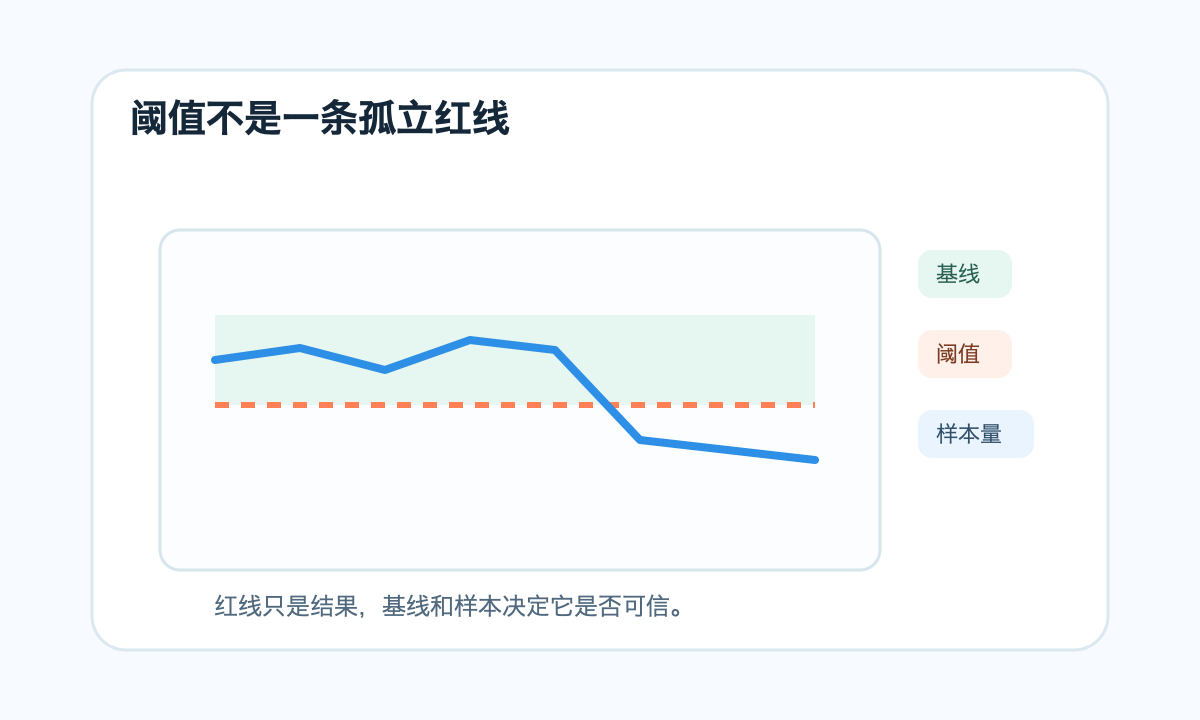
先找基线,再谈阈值
没有基线的阈值通常靠感觉。比如 CPU 超过 80% 告警、转化率低于 10% 告警、接口 P95 超过 1 秒告警。这些数字不是一定错,但如果没有结合业务时段、历史波动和样本量,就很容易误判。
转化率在工作日白天和凌晨不一样,大促期间和普通日不一样,新用户和老用户不一样。接口耗时在缓存热和冷启动时也不一样。基线不是一个固定平均值,而是一段可解释的正常范围。
做阈值前,至少看过去一段时间的分布:平均值、P50、P95、最大最小、波动区间、周期性。很多指标都有时间规律,周末低、工作日高,上午低、下午高。如果用一个全局阈值覆盖所有时段,告警质量会很差。
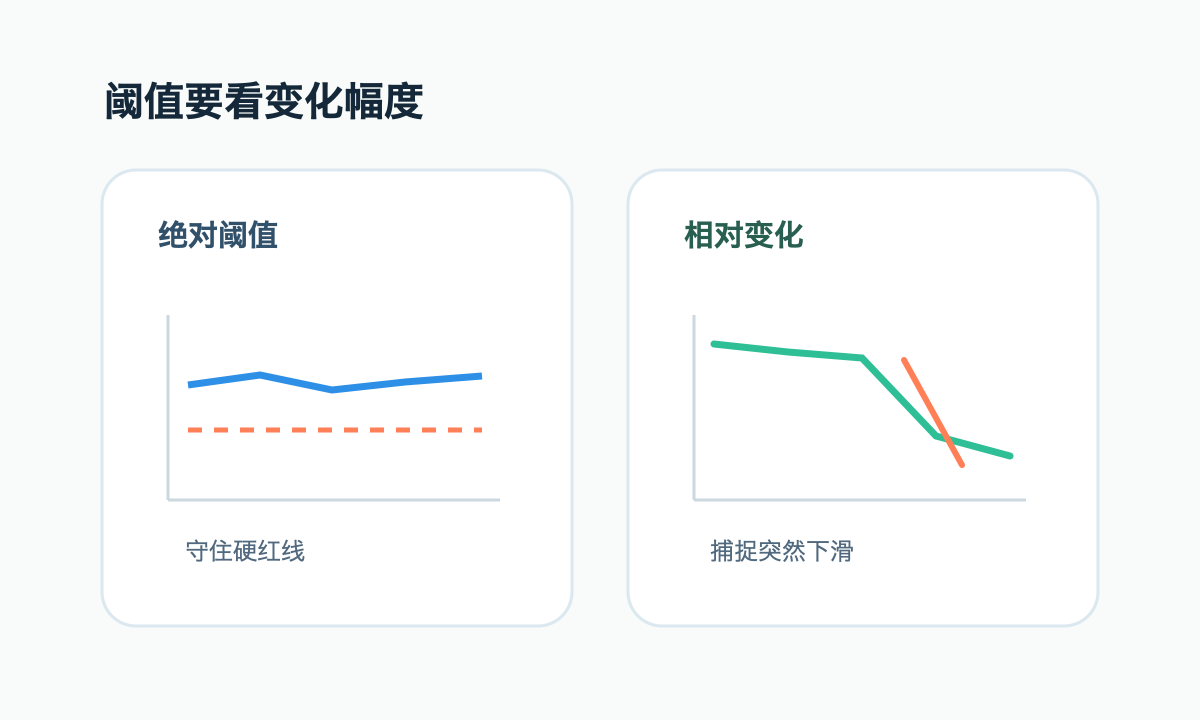
绝对阈值和相对阈值要搭配
绝对阈值适合有明确业务红线的指标。比如支付成功率低于某个值、错误率高于某个值、队列积压超过某个数量。这类阈值清楚,便于响应。
但很多异常不是绝对值越界,而是相对变化。转化率从 40% 掉到 25%,绝对值还不算低,但对业务已经很严重。接口耗时从 80ms 涨到 300ms,没超过 1 秒,却可能说明依赖开始抖动。相对阈值能更早发现趋势。
比较稳的做法是两者结合:绝对阈值兜底,相对阈值捕捉突变。比如“支付成功率低于 90%”或“较过去七天同时间段下降超过 20%”。这样既能发现极端异常,也能发现对当前业务有意义的下滑。
样本量太小时不要急着报警
很多比例指标会被小样本骗。10 个用户里失败 2 个,失败率 20%;10000 个用户里失败 200 个,也是 2%。两者的告警意义完全不同。如果不看样本量,小流量页面会频繁误报。
比例类指标最好加最小样本门槛。比如曝光量超过 1000 后再判断转化率,订单量超过 100 后再判断支付成功率。样本不足时可以显示观察状态,而不是直接报警。
样本量门槛也要结合业务。高价值低频业务不能等太多样本,比如大额支付、企业合同审批,少量失败也值得关注。低价值高频业务则更需要统计稳定性。阈值不是纯数学问题,背后是业务风险。
还有一个容易忽略的问题:样本量不是只看分母,还要看数据来源是否稳定。比如某个渠道埋点延迟了,曝光数突然变少,转化率看起来可能异常升高;某个端的上报失败了,失败率可能反而变低。看板如果只展示最终比例,不展示采集量、上报延迟和数据新鲜度,阈值就会被脏数据牵着走。
所以比例指标至少要配一两个健康检查指标。转化率旁边放曝光量、点击量和数据延迟;错误率旁边放请求量和日志采样状态;支付成功率旁边放订单量、回调延迟和渠道分布。告警触发时先确认数据本身可信,再判断业务是否真的异常。这个顺序看起来麻烦,但能减少很多“指标坏了还是业务坏了”的争论。
如果团队还没有精细的数据质量监控,可以先用简单规则兜住:数据延迟超过某个时间,不触发业务异常告警,而是触发数据链路告警;核心分母低于最低样本门槛,页面展示观察态;某个采集端缺数,告警文案里明确标出“数据不完整”。让告警承认不确定性,比硬装确定更可靠。
告警级别要对应动作
一个指标异常后,谁处理、多久处理、怎么处理,应该在告警规则里写清楚。没有动作的告警只是噪音。
可以把告警分成几级。提示级只进看板或日报,提醒大家观察趋势;普通告警进工作群,需要负责人在一段时间内确认;严重告警电话或值班系统通知,需要立刻处理;灾难级告警触发预案,比如限流、回滚、切换配置。
不同级别的阈值应该不同。比如错误率 1% 进入观察,3% 群通知,10% 电话告警。不要所有异常都用同一个响铃方式。告警多了,大家会自然忽略,最后真正严重的也没人看。
多指标组合比单指标更可靠
单个指标经常解释不完整。转化率下降可能是页面问题,也可能是投放人群变化;接口耗时上升可能是服务问题,也可能是下游依赖;订单量下降可能是活动结束,也可能是支付失败。
组合指标能减少误判。比如转化率下降同时页面错误率上升,前端问题概率更高;支付成功率下降同时支付回调延迟上升,依赖问题更明显;接口 P95 上升同时数据库慢查询上升,瓶颈可能在数据库。
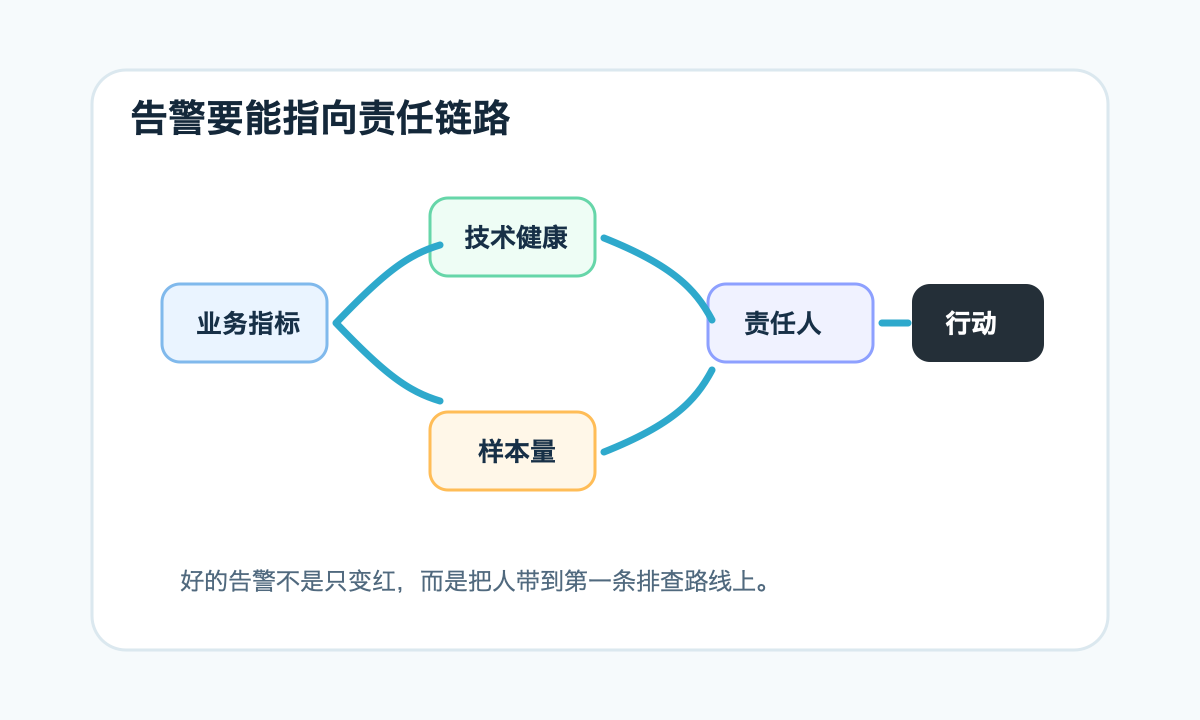
当然,组合规则不要过度复杂。规则越复杂,越难解释,也越容易漏报。可以先从少数关键组合开始:业务结果指标 + 技术健康指标 + 样本量。能解释 80% 问题就很好。
组合规则的重点不是把所有指标塞进一个巨大表达式,而是让告警能给出第一条排查路线。比如“转化率下降 + 前端 JS 错误上升”应该直接指向前端监控和最近发布记录;“支付成功率下降 + 回调延迟上升”应该指向支付渠道和消息队列;“接口 P95 上升 + 错误率不变”可能先看慢查询、缓存命中和连接池,而不是马上判断业务故障。
这类规则最好和责任边界一起设计。每条告警都应该知道默认负责人是谁,关联看板在哪里,第一步排查命令或页面是什么。否则组合指标只是更复杂的红灯,值班同学仍然要从头猜。告警文案可以短,但信息要完整:当前值、基线值、变化幅度、样本量、影响范围、建议入口。
我更倾向于先做少量高质量组合告警,而不是给每个指标都配一套复杂规则。核心链路通常就几条:注册、登录、下单、支付、履约、内容发布。每条链路挑 3-5 个关键指标,把结果、过程和技术健康串起来,先让这些告警可信。等团队对误报和漏报有记录,再逐步细化。
阈值要有过期时间
业务会变,阈值也会过期。新用户增长、产品改版、接口优化、活动策略变化都会改变基线。如果阈值多年不动,它迟早会变成摆设。
建议给关键告警规则设置复查周期。比如每月看一次误报、漏报和响应耗时;大版本上线后重新校验核心指标基线;大促前单独调整阈值和通知策略。阈值不是配置完就结束,它需要维护。
告警复盘时也要记录规则是否有效。一次事故没有报警,是阈值太松、样本门槛太高、数据延迟,还是指标选错了?一次误报太多,是阈值太紧、周期性没处理,还是告警级别不合理?这些问题要回到规则本身。
规则维护还需要明确主人。很多团队的问题不是没有告警,而是没人承认这条告警归自己管。技术同学觉得这是业务指标,业务同学觉得这是数据平台配置,数据同学又只负责报表计算。结果阈值出了问题,谁都能解释,谁都不改。
一个可执行的做法是给每条核心告警加 owner、复查周期和最近变更原因。owner 不一定是一个人,可以是一个小组,但必须有人收到误报反馈后能改规则。复查周期不用太频繁,关键链路月度复查,普通指标季度复查即可。最近变更原因要写人话,例如“新支付渠道上线后基线提高”或“活动期间样本波动增大,临时提高样本门槛”。
阈值变更也要有轻量记录。不要让大家只在配置平台里改一个数字。至少记录旧值、新值、依据、预计影响和回滚方式。这样下次事故复盘时,能知道规则为什么变成现在这样,而不是面对一堆历史配置猜考古。
看板展示要说明阈值含义
很多看板只画红线,却不说明红线是什么意思。业务同学看到红线,会以为下面就是严重事故;技术同学看到红线,可能知道只是观察线。理解不一致,会导致沟通成本。
看板上最好展示阈值类型、基线来源、样本门槛和最近更新时间。文字不用多,但要让读者知道这条线是怎么来的。对于重要指标,可以显示“当前较七日同周期下降 18%”而不是只显示一个红色数字。
如果指标处于观察状态,也要明确标记。比如样本不足、数据延迟、规则维护中。不要让用户把不完整数据当成最终结论。
发布前要演练一次告警
告警规则上线前,不要只看配置保存成功。最好用历史数据回放,看看规则会触发多少次,是否符合预期;也可以人工构造一段异常数据,验证通知链路、负责人、升级策略是否生效。
如果一条告警发出去后没人知道该做什么,它就还没准备好。如果告警信息里没有指标值、变化幅度、影响范围、关联看板和处理建议,值班同学还要重新查半天。好的告警应该直接把人带到排查入口。
演练时可以准备三个用例。第一个是真异常:用历史事故数据回放,确认规则能触发,级别也合适。第二个是假异常:选择一次正常波动或小样本波动,确认规则不会把它升级成严重告警。第三个是数据链路异常:模拟数据延迟或缺数,确认系统提示的是数据质量问题,而不是误导大家去排查业务。
这三个用例能覆盖大部分阈值问题。真异常测漏报,假异常测误报,数据链路异常测解释能力。只要其中一个过不了,就不要急着把告警接入电话通知。先放到观察级,看一段时间触发记录,再决定是否升级。告警系统的信任感是慢慢建立的,一开始就狂响,只会让大家更快学会忽略它。
真正上线后,也要看告警的“命中质量”。可以每周统计触发次数、确认次数、有效事故数、平均确认耗时、升级次数和关闭原因。不是为了做复杂报表,而是为了发现规则是否还在帮助团队。一个月触发几十次但没有一次需要处理的告警,就应该降级或重写;一次严重事故没有触发的规则,要么补充组合条件,要么调整基线和样本门槛。
最后给一个判断标准:阈值不是为了让看板变红,而是为了让正确的人在正确时间做正确动作。如果一条阈值无法解释基线、样本、风险和响应动作,它就还只是一个数字,不是告警规则。