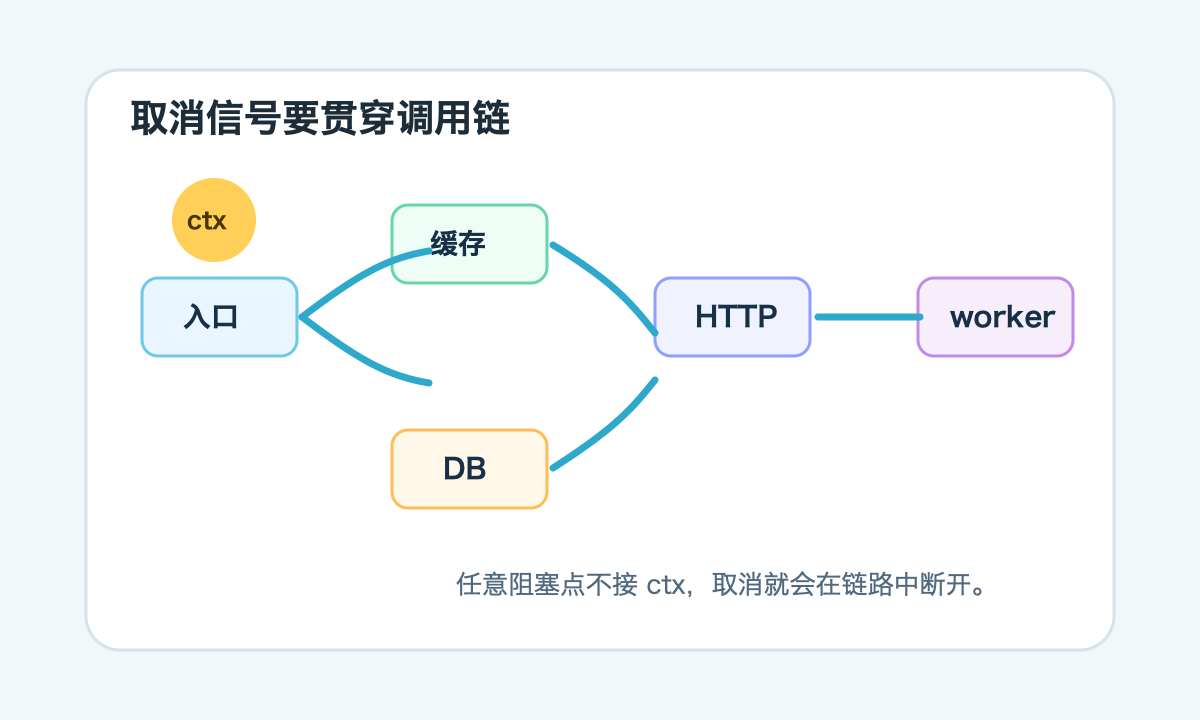
一次 Go 服务发布,旧实例迟迟停不下来。Kubernetes 已经发了终止信号,新的 Pod 也起来了,但旧实例里还有一批后台任务继续跑,数据库连接一直占着。排查后发现,入口层确实创建了 context.Context,请求超时也能触发取消;可任务内部调用外部接口、写数据库、等待队列时,有几段代码没有接这个 context。取消信号到了入口,却没有传到底。
Context 取消不是 Go 代码里的礼貌参数,也不是为了让函数签名看起来专业。它是资源边界:请求不需要了,任务被撤销了,实例要下线了,总预算用完了,下游就应该尽快停。只在最外层传一个 ctx,没有让每一段阻塞操作都感知它,等于只是把边界写在纸上。
取消信号不是错误处理的替代品
很多人会把 ctx 当成错误处理的一种:发现 ctx.Done() 就 return。这个方向没错,但它不等于完整错误处理。取消是一类特殊结果,它和业务失败、依赖超时、参数错误不一样。用户主动取消、服务下线取消、超时预算取消,后续动作也不一样。
比如用户取消导出任务,系统应该把任务状态标成已取消;服务发布导致任务停止,可能要进入可恢复队列;请求总超时,可能要记录超时指标并提醒调用方。所有情况都写成普通 error,会让任务平台看不出区别。
Go 里 context.Canceled 和 context.DeadlineExceeded 本身就提供了语义。关键是不要在中间层随手包掉,导致上层无法识别。日志里也要保留取消原因,否则排查时只能看到“任务失败”。
每一段阻塞都要接住 ctx
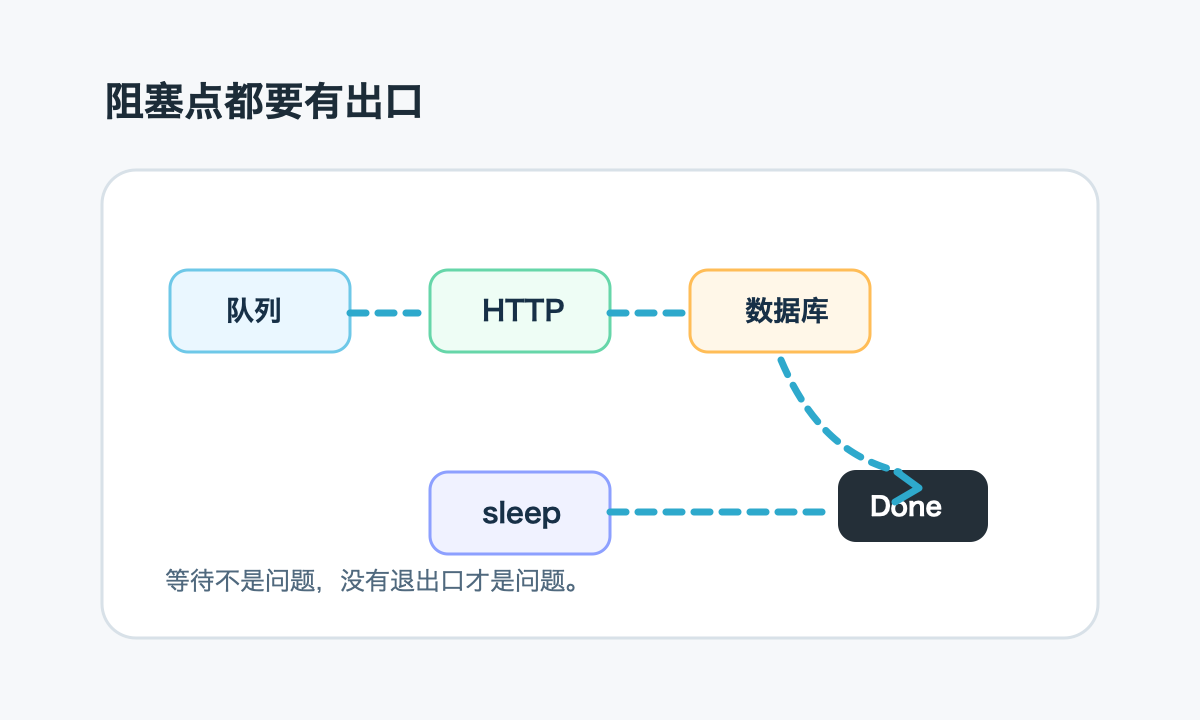
取消能不能生效,取决于阻塞点是否尊重 ctx。常见阻塞点包括 HTTP 请求、数据库查询、channel 等待、锁等待、队列消费、sleep、外部 SDK 调用。只要其中一段不接 ctx,整条链路就可能卡住。
HTTP 请求要用 http.NewRequestWithContext,数据库要用 QueryContext、ExecContext,等待 channel 时要用 select 监听 ctx.Done()。如果只是普通 time.Sleep,取消期间也不会醒来;可以改成 select 加 timer。
- select {
- case item := <-queue:
- return handle(ctx, item)
- case <-ctx.Done():
- return ctx.Err()
- }
这段代码的价值不是写法本身,而是让等待动作有退出口。很多后台任务就是卡在“等一个东西”上,队列没消息、锁没释放、依赖没响应。没有 ctx,等待就没有边界。
不要创建一个新 context 抹掉上游边界
有些代码为了方便,会在函数内部重新写 context.Background()。这在工具函数里很常见,也很危险。上游传来的取消信号和 deadline 会被抹掉,下游操作变成不受控。
- func SaveOrder(order Order) error {
- ctx := context.Background()
- _, err := db.ExecContext(ctx, "insert ...")
- return err
- }
这个函数看起来能跑,但它不尊重调用方。如果请求已经超时,数据库写入仍然继续;如果服务正在下线,它也不知道。更好的写法是把 ctx 作为参数传进来。
- func SaveOrder(ctx context.Context, order Order) error {
- _, err := db.ExecContext(ctx, "insert ...")
- return err
- }
当然,不是所有地方都应该直接使用请求 ctx。异步任务如果需要在请求结束后继续执行,就不能简单复用请求 ctx。但这不代表用 Background,而是要创建任务自己的 ctx,并定义任务级 deadline 和取消入口。重点是每个生命周期都有明确主人。
deadline 要按预算拆,不要全链路一个数字
只设置一个请求超时,通常不够。一次操作可能包括鉴权、查缓存、查数据库、调用外部服务、写日志。总预算是 3 秒,不代表每一步都可以等 3 秒。否则任意一步耗尽预算,后面就只能失败。
更稳的做法是拆预算。比如总预算 3 秒,外部接口最多 800ms,数据库最多 500ms,缓存最多 100ms。每一段都使用从上游 ctx 派生出的子 ctx。这样某个依赖不会无限占用整条链路。
但预算也不能拆得太死。真实服务会抖动,固定数字可能让系统过于脆弱。可以先从线上 P95、P99 和业务容忍度估算,再通过压测和监控调整。deadline 是技术配置,也是产品承诺:用户愿意等多久,系统就应该在这个边界内给出结果。
goroutine 泄漏常常从取消缺失开始
Go 里启动 goroutine 很容易,回收 goroutine 却要靠设计。一个 goroutine 如果在 channel 上等待、在网络请求里阻塞、在循环里 sleep,却没有监听 ctx,就可能泄漏。单个 goroutine 不大,但成千上万个挂住后,会拖慢调度、占用连接和内存。
后台 worker 最好有明确退出协议。服务收到停止信号后,关闭入口,不再接新任务;正在执行的任务收到 ctx,尽快完成或退出;超过宽限时间仍未完成的任务记录状态,交给恢复机制。不要让 goroutine 自己决定“等我忙完再说”。
如果任务不能安全中断,比如正在写入关键数据,也要把不可中断区间缩短,并在进入前检查 ctx。不可中断不是没有边界,而是边界更谨慎。
取消以后,状态不能留成半截
很多取消问题真正伤业务的地方,不是函数没有 return,而是 return 以后状态没有处理干净。一个导出任务被取消了,文件是否要删除?一笔订单同步中断了,状态是继续等待、标记失败,还是进入重试队列?一个批处理跑到第 300 条被取消,前 299 条已经写入,下次恢复从哪里开始?
这些问题不能交给 ctx 自动解决。ctx 只能告诉你“该停了”,不能替你决定“停在什么状态”。所以在设计任务时,要把取消后的状态也作为流程的一部分写清楚。短请求可以直接返回取消结果;长任务最好有任务状态机,例如 pending、running、canceling、canceled、failed、finished。收到取消信号后先进入 canceling,完成必要清理后再变成 canceled。
如果任务涉及外部副作用,比如扣库存、发通知、写审计日志,就更不能简单地在任意位置退出。比较稳的做法是把流程拆成可恢复的小步骤,每一步有明确提交点。已经提交的步骤下次不要重复执行,未提交的步骤可以重试或放弃。这样取消不会把系统留在“看起来成功了一半”的尴尬状态。
这也是我不建议把取消逻辑藏在最底层工具函数里的原因。工具函数可以尊重 ctx,业务层必须定义取消语义。比如数据库写入函数只负责在 ctx 结束时返回错误;订单服务要决定这个错误会不会改变订单状态;任务平台要决定是否允许用户再次启动。层级分清,取消才不会变成一堆互相猜测的错误处理。
第三方 SDK 不支持 ctx 怎么办
真实项目里会遇到第三方 SDK 不支持 context 的情况。直接调用它,取消就传不进去。这时可以做几层保护。
第一,优先选择支持 timeout 或 cancel 的 SDK。第二,把调用放到单独 goroutine 并用 select 等待结果和 ctx,但要知道这只能让当前逻辑返回,不能真正停止底层调用。第三,对连接池、并发数和外部请求设置独立上限,避免取消无效时拖垮系统。
这也是技术选型要看的点。一个 SDK 功能再丰富,如果关键调用不能设置超时,在线上服务里风险很高。尤其是支付、短信、风控、对象存储这类依赖,取消和超时能力应该进入选型清单。
日志要保留取消路径
取消问题排查时,最怕日志只写“context canceled”。这句话说明结果,不说明原因。你需要知道是谁取消的、在哪一步取消、已经执行了多久、任务是否可恢复。
可以在关键步骤记录 step、cost、deadline、remaining budget、cancel reason。比如任务开始时记录总预算,每个外部调用结束时记录耗时,收到 ctx.Done 时记录当前步骤。这样复盘时能判断是预算太短,还是某个依赖不尊重取消。
指标也要分开。业务失败率、超时率、取消率不要混在一起。发布期间取消率上升可能是正常下线导致;外部依赖抖动导致 DeadlineExceeded 上升,则需要看依赖链路。指标分类越清楚,排查越少猜。
上线前故意取消一次
很多服务只测正常路径,不测取消路径。上线前可以做几件事:请求发出后客户端断开,观察服务是否停止下游调用;后台任务执行中触发取消,观察状态是否正确;服务发布时终止实例,观察 goroutine 是否退出;外部接口超时,观察是否按预算返回。
这些测试不复杂,却能暴露大量隐藏问题。尤其是服务下线场景,如果没有提前测,等发布窗口里发现旧实例停不下来就很被动。
更具体一点,可以把取消测试写进接口验收。第一组测客户端主动断开,确认服务端不会继续打下游依赖;第二组测 deadline,确认超过预算后返回的是可识别的超时语义;第三组测发布下线,确认宽限时间内没有新增任务,已有任务要么完成,要么进入可恢复状态;第四组测依赖卡死,确认连接池不会被无限占满。
测试通过不代表线上永远没问题,但它能逼着代码回答几个关键问题:ctx 传到了哪里,哪里还没传到;哪些调用真的能取消,哪些只能让当前逻辑返回;取消后状态怎么落库;日志和指标能不能看出取消路径。把这些答案提前写出来,比线上靠猜要轻松得多。
最后给一个判断标准:一个 ctx 如果只传到函数签名,却没有传到阻塞操作、异步任务和日志证据里,它就还没有真正生效。Context 取消先传到底,不是为了写更标准的 Go,而是为了让系统在不需要继续时,真的停得下来。