有一次移动端线上问题,用户反馈“明明只点了一次提交,后台却出现了两条申请”。服务端日志看起来也委屈:它确实收到了两次请求,而且两次参数几乎一样。客户端同学复盘后发现,第一次提交时网络很差,App 等了几秒没有拿到响应,按钮状态又恢复成可点;用户以为没提交成功,又点了一次。第二次请求成功返回,第一次请求其实也在路上,最后两条都被服务端处理了。
这类问题很容易被归结成“按钮要禁用久一点”。但按钮只是表面。真正的问题是移动端没有把请求状态建模清楚:请求已经发出但响应未知,这个状态和“没有提交”完全不是一回事;请求失败、请求超时、请求被系统杀进程打断、请求已经进离线队列,也不是同一种失败。状态一旦混在一起,重试就会变成碰运气。
Android 里的弱网场景比桌面 Web 更复杂。用户可能在地铁里切换网络,App 可能退到后台,系统可能回收进程,DNS、TLS、网关、服务端任意一段都可能慢。你看到的是一个超时错误,真实世界里可能是请求没发出去,也可能是服务端已经处理完但响应丢了。弱网重试要先控状态,就是要承认这些不确定性,并把它们变成可以恢复、可以解释、可以去重的流程。
状态线的重点不是画得多复杂,而是不要把“响应未知”直接当成“没有发生”。这一步如果搞错,后面的重试和幂等都会被动。
超时不是失败,它只是“不知道结果”
很多代码会把超时直接当成失败,然后允许用户重新提交。这个判断在展示型请求里问题不大,比如刷新列表失败了,再刷一次就好。但对于下单、付款、申请、评论发布、资料修改这类会改变服务端状态的操作,超时更准确的含义是:客户端不知道服务端有没有处理成功。
这句话很绕,但很关键。网络请求从客户端发出后,可能在几个位置失败:还没离开本机、到达网关前失败、服务端处理前失败、服务端处理后响应失败。客户端通常只能看到一个异常类型,无法百分百判断服务端状态。如果你把所有异常都当成“没提交”,就会鼓励用户重复操作。
所以我更建议把写操作状态拆得细一点。比如提交类请求至少有:未提交、提交中、结果未知、待确认、已成功、已失败、可重试、不可重试。结果未知时,UI 不应该简单恢复成初始按钮,而应该提示用户“正在确认结果”,或者提供一个查询状态入口。
在 Android 里,这个状态不应该只放在按钮变量里。按钮变量随着页面销毁就没了,旋转屏幕、进程重建、返回页面都会丢。状态应该落在 ViewModel、Repository 或本地存储里,具体取决于操作风险。低风险请求可以只在内存里管理;高风险写操作最好有本地记录,至少能在 App 重启后知道有一笔提交处于未知状态。
这里有个取舍:不是所有请求都要做成复杂状态机。搜索联想、普通列表刷新、点赞这种低成本操作,可以轻量处理。但涉及金钱、库存、审批、身份资料、业务申请的操作,状态一定要严肃。越靠近真实业务结果,越不能只靠按钮 disabled 来防重复。
重试预算比“失败就重试”靠谱
弱网重试最容易写成一行规则:失败了就重试三次。问题是,不同失败完全不一样。网络断开时立刻重试三次没有意义;服务端 500 时连续重试可能放大压力;参数错误永远不该重试;超时则要看业务是否允许重复提交。
更合理的做法是给重试设置预算。预算包括次数、间隔、触发条件、网络条件和业务风险。比如读取类请求可以重试 2-3 次,间隔递增;提交类请求只在明确没有到达服务端时自动重试;结果未知时不直接重复提交,而是先查询状态;参数校验错误直接停止。
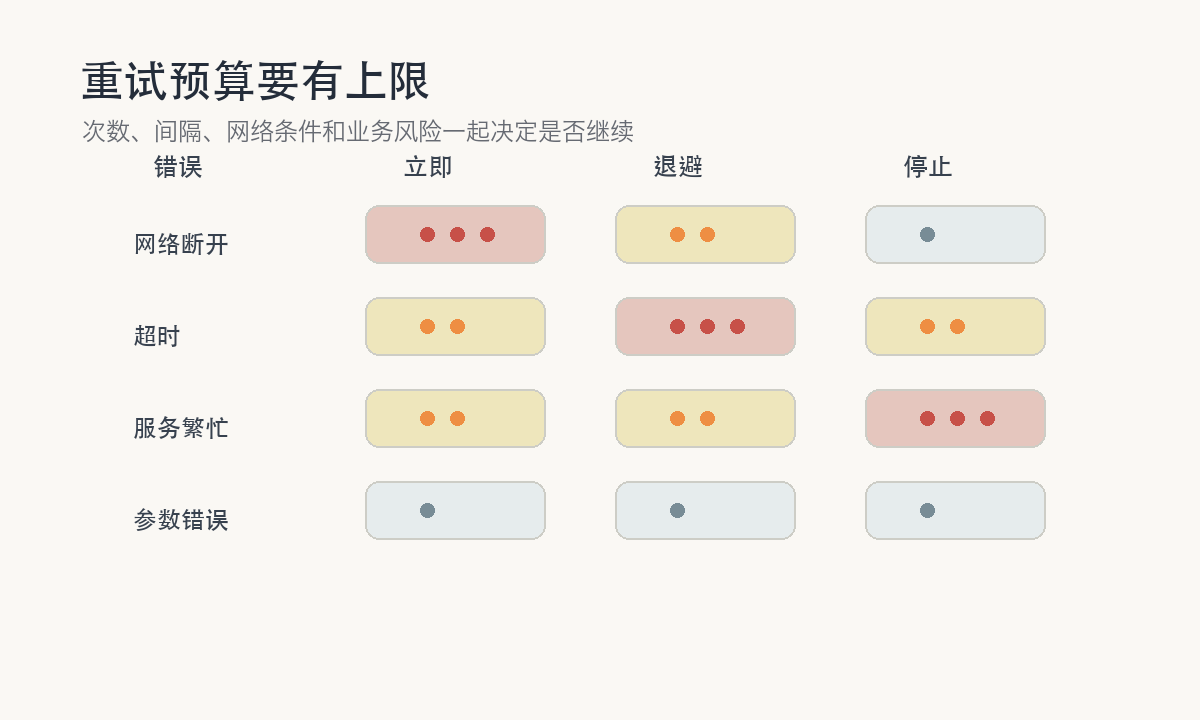
矩阵里的点不是固定答案,而是提醒你:重试不是一个全局开关。错误类型、业务风险和网络条件要一起看。
Android 里可以用指数退避来减少冲击。第一次失败后等 1 秒,第二次等 3 秒,第三次等 8 秒,并加一点随机抖动,避免大量客户端同时重试。如果是后台任务,可以交给 WorkManager,让它根据网络条件、充电状态和系统调度安排执行。但 WorkManager 也不是魔法,它只能帮你调度,不能替你解决幂等和状态定义。
还有一个常见误区是把所有异常都塞进同一个 catch 里。真实项目里最好把异常分层:无网络、超时、服务端错误、客户端参数错误、认证失效、业务拒绝。它们对应的 UI 提示、重试策略和日志级别都不同。无网络可以等网络恢复;认证失效应该引导登录;业务拒绝要展示原因;超时要进入结果确认。
重试预算还要有退出条件。用户离开页面、取消操作、请求已经成功、业务状态已经关闭,都应该停止重试。否则后台队列里会留下很多没有意义的旧任务,等网络恢复时一起冲向服务端。
离线队列要记录足够多的现场
一些团队会说:“那我们把失败请求放进离线队列,网络好了再发。”方向是对的,但离线队列不是把 URL 和 body 存起来这么简单。你需要记录足够多的现场,否则恢复时很难判断这条请求是否还应该执行。
一条可靠的离线任务至少要包含:业务类型、请求参数、幂等键、创建时间、最近尝试时间、尝试次数、最后一次错误、当前状态、用户身份或租户信息。对于高风险操作,还要记录可查询的业务单号。这样 App 重启后才能知道,这条任务是新建、执行中、等待网络、需要确认,还是已经不应该继续。
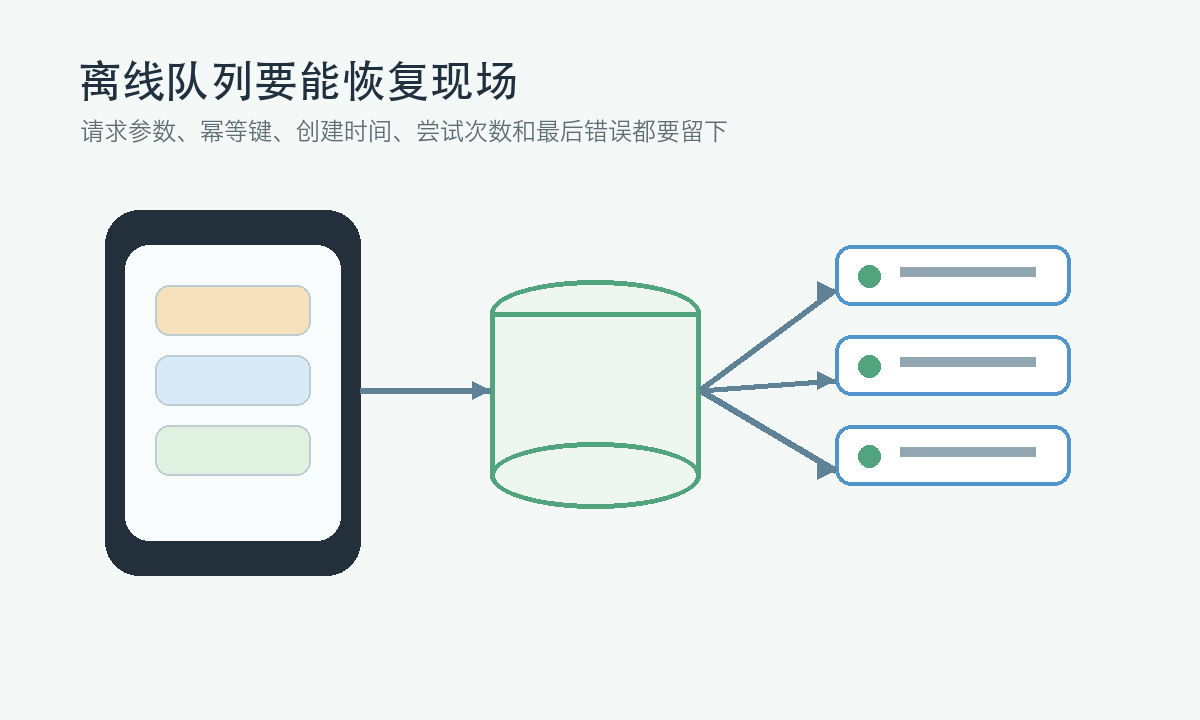
这张图想表达的是:离线队列不是客户端自己的小仓库,它必须和服务端幂等、状态查询、监控日志连起来,才不会变成重复提交机器。
离线队列还要考虑任务过期。比如一个活动报名请求,活动结束后再重试就没有意义;一条修改昵称请求,如果用户后来又改了一次,旧任务也不应该继续执行。队列里的任务不能无限期等待,必须有业务上的有效期。
任务顺序也要小心。某些请求可以乱序执行,比如上传日志;某些请求必须保持顺序,比如先创建草稿再上传附件,先加入购物车再修改数量。如果队列不区分这些依赖,网络恢复后并发执行,可能会制造新的状态错乱。
我的建议是先把离线任务分级。低风险任务可以自动重试;中风险任务可以自动重试但要有次数和过期时间;高风险任务进入待确认状态,网络恢复后先查询服务端结果,再决定是否继续。这样用户体验会稍微复杂一点,但能显著降低重复写入的风险。
幂等键要从客户端生成,也要被服务端认真使用
弱网重试离不开幂等。客户端可以控制状态,但只要请求可能重复到达服务端,服务端就必须知道这几次请求是不是同一个业务动作。幂等键就是用来表达“这是同一次操作”的标识。
幂等键最好在用户发起操作时生成,而不是每次请求重试时重新生成。比如用户点击提交申请,客户端生成一个 operationId,后续无论自动重试、手动确认、App 重启恢复,都带同一个 operationId。服务端看到同一个 operationId,就返回同一笔处理结果,而不是创建新记录。
幂等键不能太随意。只用时间戳可能碰撞,只用用户 id 可能把不同操作混在一起。更稳的做法是结合业务类型、用户、客户端生成的 UUID,必要时加上业务对象 id。服务端还要存储处理结果和状态,不能只是简单判断“见过这个 key 就拒绝”。因为客户端重试时需要知道之前到底成功、失败还是处理中。
有些操作天然有业务单号,比如订单号、申请单号、支付流水号,这些可以成为幂等基础。但如果单号是服务端创建的,客户端第一次请求超时时可能拿不到单号,这时客户端 operationId 仍然有价值。它可以帮助服务端把第一次请求和后续查询关联起来。
这里的取舍是:幂等不是前端单方面能完成的事。客户端可以生成稳定标识,服务端必须配合存储和查询。如果后端接口完全不支持幂等,客户端只能做 UI 防重复和状态确认,不能保证最终不会重复写入。高风险业务里,这种接口应该推动改造,而不是靠客户端硬扛。
UI 提示要告诉用户“系统在做什么”
弱网下最容易诱发重复操作的是不确定感。用户点击后没反应、按钮忽明忽暗、toast 一闪而过,他自然会再点。好的 UI 不只是显示 loading,而是告诉用户当前动作处在什么阶段。
提交中可以显示“正在提交”;结果未知可以显示“正在确认提交结果”;进入离线队列可以显示“网络恢复后继续提交”;不可重试失败要明确告诉用户原因;可重试失败可以给出手动重试入口。不同状态对应不同文案,用户才不会把所有失败都理解成“刚才没点上”。
按钮状态也要和业务状态绑定。不要只在请求发出时 disabled,然后 catch 里立刻恢复。对于结果未知状态,按钮可以变成“查看处理结果”或“继续等待”,而不是再提交一次。对于离线队列任务,页面再次打开时应该能看到当前任务状态,而不是像什么都没发生过。
还有一个细节:多端场景下,移动端本地状态可能落后于服务端。比如用户在 Web 端已经完成操作,Android 端离线任务还在等待。恢复时先查服务端状态,再决定是否提交,可以避免很多重复动作。弱网重试不是只盯着本机队列,也要尊重服务端已经发生的结果。
上线前要专门测“响应丢了”
弱网测试不能只断网再恢复。真正危险的是请求已经到达服务端,但客户端没有收到响应。这个场景如果不测,很容易误以为重试逻辑安全。
上线前至少要模拟几类情况:请求发出前无网络、请求发出后超时、服务端处理成功但响应丢失、App 退后台后恢复、进程被杀后重启、网络从 Wi-Fi 切到蜂窝、离线队列执行到一半失败。每个场景都要看本地状态、服务端记录、幂等结果和用户提示是否一致。
日志也要跟上。客户端日志里要能看到 operationId、任务状态、尝试次数、错误类型、网络状态;服务端日志里也要能按 operationId 查到处理结果。否则线上出现重复提交时,双方只能各查各的,很难把链路拼起来。
最后给一个判断标准:如果一个写操作在弱网下超时后,你无法回答“服务端可能发生了什么、客户端现在该显示什么、再次点击会不会重复、App 重启后怎么恢复”,那它就还没有完成弱网设计。重试不是让请求多跑几次,而是让不确定状态有边界、有证据、有退路。