有一次后台任务上线,问题不是服务写得慢,而是大家太相信“多开几个 goroutine 就好了”。任务入口来自运营后台,一次批量导入会产生几万条记录;每条记录要查库存、写状态、发一条通知,还要回调第三方接口。开发同学把处理逻辑拆成 goroutine,看起来很 Go,也很利落。压测时本机跑得飞快,真到线上,队列开始积压,数据库连接池被打满,第三方接口偶尔返回 429,最后连后台页面也变慢了。
这类事故很常见。Go 的并发能力给了我们很低的启动成本,但低成本不等于没有成本。一个 goroutine 的内存占用不大,调度也轻,可它后面挂着数据库连接、HTTP 请求、锁等待、缓存写入和重试逻辑时,真正的压力并不在 goroutine 本身,而在它把多少下游资源同时拉进来。
所以做后台任务时,我更愿意先问一个有点朴素的问题:这批任务最多允许多少个同时进入危险区?危险区可能是外部接口,可能是数据库事务,也可能是一段会竞争同一把锁的业务代码。这个问题问清楚,后面的 Worker 数量、队列长度、超时时间和重试策略才有地方落脚。

上图想表达的是一个简单判断:入口快不代表系统快,入口只是把压力搬到了队列和下游。真正需要控制的是压力在链路里的扩散方式。
入口先拦住,别让队列替你背锅
很多后台任务的第一版实现,都会把队列当成缓冲区。只要用户点了提交,任务先塞进队列,页面提示“处理中”,系统看起来就很顺。但队列只能延迟问题,不能消灭问题。如果入口没有限制,队列会变成一个没有人负责的承诺:你把任务收下来了,却不知道什么时候能处理完,也不知道处理中途会不会因为依赖服务降级而失败。
入口控制不是简单拒绝用户,而是给任务一个明确的容量边界。比如一次导入最多允许 5000 条;同一个租户同时只能有 1 个活跃导入任务;低优先级任务在系统繁忙时进入延迟队列;需要调用外部接口的任务必须展示预计耗时。这些限制看起来像产品约束,其实是工程稳定性的第一层保护。
在 Go 里,入口控制可以落在几个位置。最粗的一层是业务层限额,直接决定是否创建任务。第二层是队列写入前的容量检查,例如 Redis Stream、Kafka 或数据库任务表都有待处理数量,超过阈值就让用户稍后再试。第三层是执行器内部的并发阀门,保证就算入口误放,执行阶段也不会把下游打穿。
我不太建议一上来就只写一个很漂亮的 Worker Pool,然后把所有压力都交给它。Worker Pool 能限制执行并发,却不能约束任务被接收的速度。入口继续放水,队列继续膨胀,用户继续以为任务已经进入处理,运营同学就会不断催“为什么还没完成”。最后你会发现,技术问题变成了沟通问题。
更好的做法是把任务状态设计清楚。一个批量任务至少要有:待校验、待执行、执行中、部分失败、已完成、已取消这几个状态。入口只负责创建可承诺的任务,不能承诺的任务就给出原因。队列只是承载执行顺序,不承担业务承诺。
Worker 数量不是拍脑袋,是由瓶颈倒推出来的
Worker 数到底开多少,经常被写成配置项,然后默认值随手填 10 或 20。这个数字如果没有依据,后面就很难排查:慢了不知道该加 Worker,失败多了不知道该减 Worker,出现抖动时只能靠感觉调参。
一个实用的倒推方法是先找最窄的下游资源。假设任务主要耗时在外部 HTTP 接口,第三方明确限制每秒 50 次请求,平均耗时 200ms,那么并发量大约可以从 QPS RT 估一个基础值:50 0.2 = 10。考虑网络波动和业务处理时间,可以把 Worker 上限放在 8 到 12 之间,然后用令牌桶限制每秒请求数。这里的关键不是公式多精确,而是 Worker 数要和真实瓶颈有关系。
如果瓶颈在数据库,就要看连接池、事务耗时、锁冲突和慢查询。数据库连接池最大 50,并不表示任务并发可以开 50,因为服务里还有别的请求也要用连接。后台任务应当只拿到一部分预算,例如 10 到 15。否则批量任务一跑,用户的普通查询也会一起变慢。
下面是一段足够朴素的执行器骨架。它不追求炫技,重点是把并发数量、取消信号和错误收集放在同一个地方:
- func RunJobs(ctx context.Context, jobs <-chan Job, workers int, handle func(context.Context, Job) error) []error {
- var wg sync.WaitGroup
- errCh := make(chan error, workers)
- for i := 0; i < workers; i++ {
- wg.Add(1)
- go func() {
- defer wg.Done()
- for {
- select {
- case <-ctx.Done():
- return
- case job, ok := <-jobs:
- if !ok {
- return
- }
- if err := handle(ctx, job); err != nil {
- errCh <- err
- }
- }
- }
- }()
- }
- wg.Wait()
- close(errCh)
- var errs []error
- for err := range errCh {
- errs = append(errs, err)
- }
- return errs
- }
这段代码还不能直接拿去做生产系统,因为它缺少任务持久化、重试、进度更新和限速。但它把一个重要边界写出来了:Worker 是执行槽位,不是业务状态本身。业务状态应该保存在任务表或队列系统中,执行器只是从中取任务并推进状态。
我见过一种很危险的写法:每来一个任务就 go handle(job),然后在 handle 里自己重试、自己写日志、自己更新状态。短期看最简单,长期看最难管。你不知道系统里到底有多少任务正在跑,也无法优雅停止,更难在发布、重启、限流时做统一处理。
超时和取消要从入口传到最后一跳
Go 的 context.Context 经常被当成函数参数的仪式感,传是传了,但真正有用的地方不多。后台任务里,context 的价值很具体:当任务被取消、服务准备下线、用户撤销操作、上游超时预算用完时,它要让整条执行链停止继续消耗资源。
一个常见失败方式是只在 Worker 循环里检查 ctx.Done(),但任务内部的 HTTP 请求、数据库查询和外部 SDK 调用没有使用这个 ctx。结果 Worker 看似支持取消,实际上已经发出去的请求仍然在跑。取消变成了“下一个任务不跑”,而不是“当前任务尽快停”。
更稳的做法是把超时预算拆开。整批任务有一个总超时,单个任务有一个执行超时,外部接口有更短的请求超时。比如批量任务最多运行 30 分钟,单条任务最多 20 秒,第三方接口最多 3 秒。这样某个外部接口抖动时,不会把所有 Worker 都挂住。
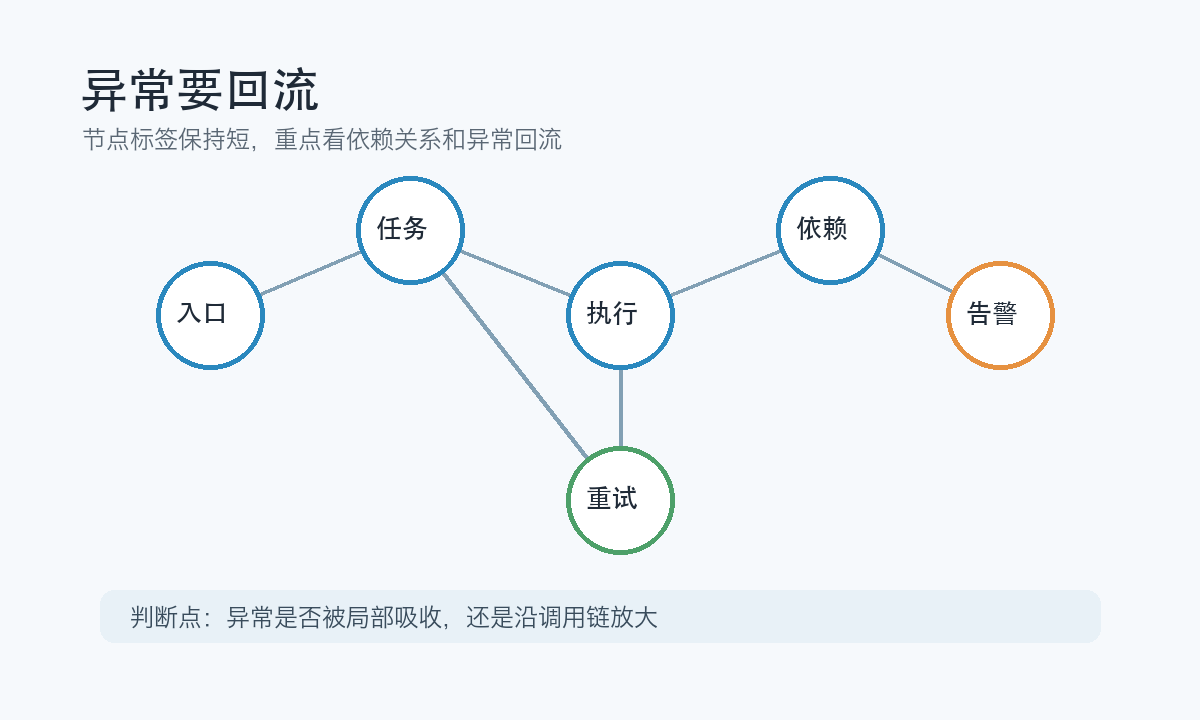
图里的异常回流是关键:失败不能只往后传,也要被局部吸收。可重试的错误进入重试队列,不可重试的错误进入失败明细,超时错误要计入依赖健康度。这样你才能知道是任务本身有问题,还是下游服务正在拖慢执行。
重试也要小心。后台任务里的重试如果没有退避和上限,很容易把一次依赖抖动放大成持续攻击。比较稳的策略是指数退避加随机抖动,例如第一次 1 秒,第二次 3 秒,第三次 8 秒,并且给每类错误设置最大次数。对于明显不可重试的错误,比如参数非法、权限不足、业务状态不存在,应该立刻落失败明细,不要浪费执行槽位。
还有一个容易被忽略的点:取消和重试都应该写入任务结果。用户取消了任务,结果不是失败;系统超时停止了任务,也不等于业务失败。状态如果混在一起,后续报表会变脏,运营同学也无法判断到底是用户操作、系统保护,还是代码缺陷。
队列长度要能说明问题,而不是只显示数字
很多系统会监控队列长度,但只看长度不够。队列长度 1000 不一定危险,关键要看任务平均处理耗时、进入速度、消费速度和最老任务等待时间。一个长度 1000、每秒消费 200 的队列很快就清空;一个长度 100、每分钟只消费 1 的队列反而说明系统卡住了。
我会把后台任务至少拆成四个指标:待处理数量、执行中数量、失败率、最老等待时间。再加两个下游指标:依赖接口耗时和数据库慢查询。这样排查时能快速判断:是入口流量太大,还是执行器太慢,还是外部依赖拖住,还是失败重试把队列填满。
这些指标最好和任务维度关联起来。比如同一个任务类型的队列情况、同一个租户的任务积压、同一个外部接口导致的失败数量。如果只看全局队列长度,很容易被平均值骗过去。一个租户的任务卡住,可能不会让全局指标爆红,但对这个租户来说就是事故。
日志也要有结构。至少包含 task_id、job_id、tenant_id、worker_id、attempt、cost_ms、error_type。不要只写“任务执行失败”。当失败率上升时,结构化日志能让你按错误类型聚合;当某个任务跑太久时,能顺着 task_id 找到每一步耗时。
这里有个取舍:不要一开始就把任务系统做成复杂的分布式调度平台。如果只是一个中等规模后台,数据库任务表加固定 Worker 就够用。真正需要引入 Kafka、Redis Stream 或专门调度系统,通常是因为任务量、可靠性、跨服务协作或削峰需求已经超过简单方案。技术选型应该跟压力来源匹配,而不是跟工具流行程度匹配。
把背压做成用户能理解的反馈
背压这个词听起来偏底层,放在业务里其实就是“系统忙不过来时,怎么让上游慢下来”。后台任务的上游不一定是另一个服务,也可能是人。运营同学连续点十次导入,产品后台不断提交批量更新,客服批量补发通知,这些都是上游。
如果系统只在内部限流,用户看到的是任务一直等待,体验会很差。更好的方式是把背压翻译成业务反馈:当前同类型任务正在执行,请等待完成后再提交;预计排队 12 分钟;本次导入超过单次上限,请拆分;外部服务繁忙,任务将延迟重试。这样的提示看起来不是技术细节,却能减少重复提交,也能降低沟通成本。
有些场景还需要优先级。比如财务结算任务优先于营销消息补发,人工触发的小批量修复优先于定时大批量扫描。优先级不是简单插队,最好和资源预算绑定。高优先级任务拿到更多 Worker 槽位,低优先级任务在高峰期放慢。否则所有任务都标成高优先级,优先级就没有意义。
如果你已经有多个任务类型,可以考虑把执行器拆成不同池子,而不是所有任务共用一个大池。共用大池的优点是简单,缺点是一个任务类型可能把资源吃完。分池的优点是隔离,缺点是资源利用率可能下降。我的经验是:任务类型少、依赖相似时先共用;任务类型多、依赖差异大、失败影响不同,就分池。尤其是会调用外部服务的任务,不要和只写本地数据库的任务抢同一批槽位。
上线前用三组数字做验收
并发控制上线前,不要只看“任务能不能跑完”。跑完只是最低要求。更有用的是三组数字。
第一组是容量数字:入口每分钟最多接收多少任务,队列长度超过多少开始拒绝,Worker 数量是多少,外部接口 QPS 上限是多少。它们决定系统承诺的边界。
第二组是质量数字:单条任务成功率、平均耗时、P95 耗时、重试次数分布、不可重试错误占比。它们决定任务处理是否稳定。
第三组是影响数字:后台任务运行时,普通用户接口耗时有没有上升,数据库连接池有没有被占满,外部依赖错误率有没有升高。它们决定这个任务系统是否会伤到其他业务。
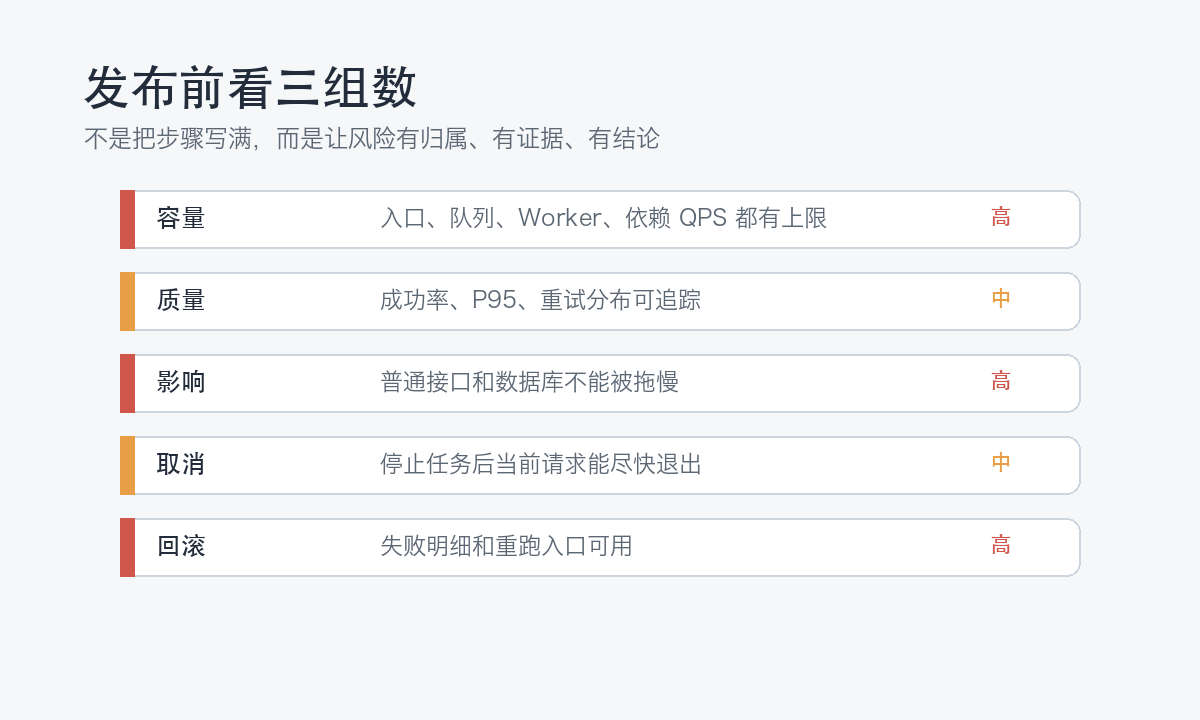
这张清单看起来简单,但能挡住很多“感觉差不多”的发布。尤其是最老等待时间和下游错误率,它们比平均耗时更早暴露问题。
最后给一个我常用的判断标准:如果你说不清一个任务系统在高峰期会拒绝什么、延迟什么、取消什么、重试什么,那它就还没有真正完成并发控制。Go 让并发变得容易,但工程上真正难的是边界。把边界写清楚,goroutine 才是在帮你;边界没写清楚,它只是让问题更快地跑到下游。