有一次活动上线前,团队给 Node.js 接口加了一个很简单的限流:同一个接口每秒最多处理固定数量的请求,超过就直接返回“请稍后再试”。压测时曲线挺好看,服务没有被打挂;正式上线后,客服却收到两类反馈:一类用户明明只是正常点击,也被挡在外面;另一类用户反复刷新,把后面的库存查询和消息队列压得很紧。接口没崩,但业务体验并不稳定。
后来复盘才发现,这个限流策略把所有压力都看成同一种东西。正常用户的短暂高峰、脚本的重复请求、某个下游服务变慢导致的排队、缓存失效后的突刺,都被同一个阈值处理。阈值低了误伤用户,阈值高了保护不了系统。限流真正要解决的不是“挡掉一些请求”,而是让系统在压力变化时还能把资源用在更值得保护的路径上。
Node.js 项目里做限流尤其容易被低估。很多服务本身是 I/O 密集型,平时看 CPU 不高,就以为还能扛;但一旦外部依赖变慢,事件循环里堆积的等待、连接池里的排队、日志和消息投递里的阻塞,会一起把尾部延迟拉长。这个时候再说“加大机器”不一定有效,因为瓶颈可能根本不在 Node 进程本身。
先弄清楚你要保护谁
限流的第一步不是选算法,而是确定保护对象。你要保护的是整个 Node 服务、某个高成本接口、数据库连接池、第三方 API、消息队列,还是某类用户体验?不同答案会导向不同策略。只在服务入口做一个总阈值,通常只能解决最粗的流量突刺,解决不了局部依赖被拖垮的问题。
比如一个内容系统里,首页推荐接口、详情接口、点赞接口和后台导出接口都在同一个服务里。首页推荐高频但可以走缓存,详情接口需要查数据库,点赞接口涉及写入,后台导出单次成本很高。如果用同一个全局阈值,后台导出可能把在线接口挤慢;如果只按接口阈值,某个用户或脚本又可能在单个接口上持续占用资源。
我更建议先画一张链路图:请求从哪里进来,经过哪些中间件,访问哪些内部模块,依赖哪些外部服务,失败后影响哪类用户。画图不是为了文档好看,而是为了看清楚限流应该落在哪些边界上。入口层、用户层、接口层、依赖层和任务层,都可能需要不同粒度的保护。
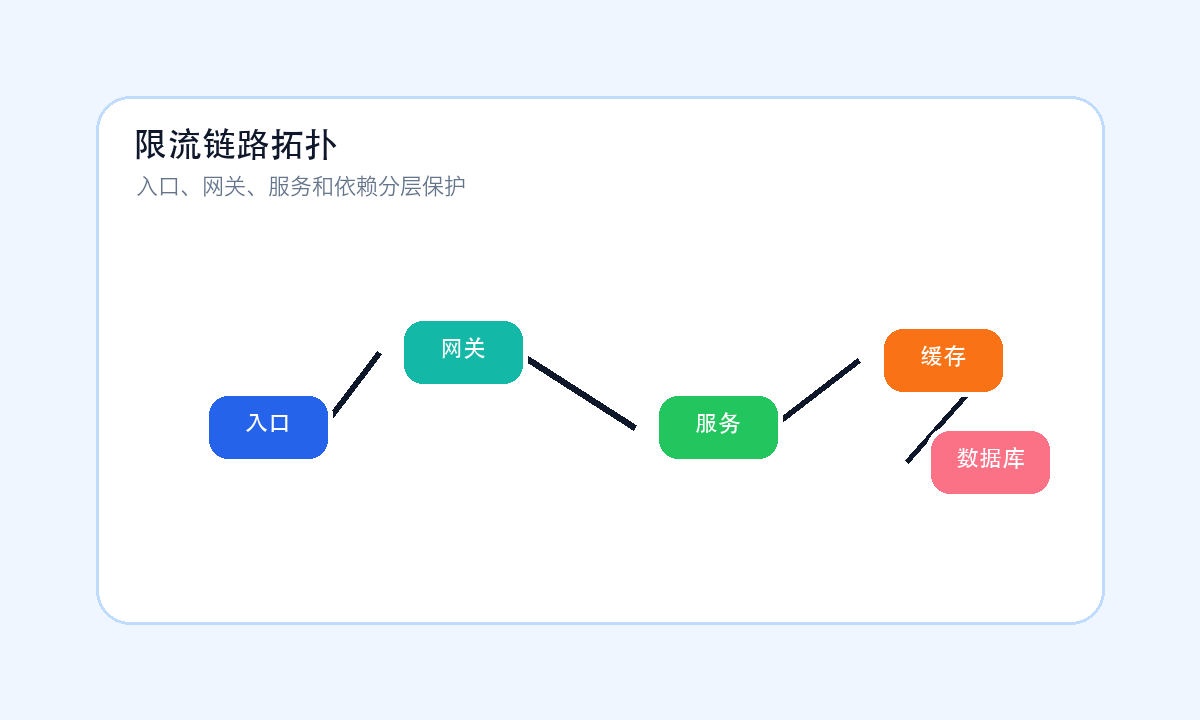
限流链路拓扑:入口层挡突刺,接口层保护高成本路径,依赖层避免下游被拖垮。它们不是互相替代,而是分工不同。
全局阈值只能做第一道门
全局限流很直观:整个服务每秒最多接收多少请求。它适合作为第一道门,尤其是在流量突然超过服务承载能力时,能避免所有接口一起被打穿。但全局阈值也很粗。它不知道请求成本差异,也不知道哪些请求更重要。
举个例子,健康检查、配置读取、详情查询、支付确认,如果都占用同一份全局配额,系统高压时可能出现低成本请求把关键路径挤掉的情况。反过来,一个特别重的导出接口只占用一次请求名额,却可能消耗很长时间的数据库连接和内存。单纯按请求数限流,会把便宜请求和昂贵请求当成同一件事。
所以全局限流最好只回答一个问题:服务整体是否已经进入危险区。危险区的信号不一定只有 QPS,还可以包括事件循环延迟、P95/P99、活跃连接数、队列长度、错误率、下游超时率。如果只用固定 QPS 阈值,流量模型一变就容易误判。工作日的 1000 QPS 和活动秒杀的 1000 QPS,对系统压力可能完全不同。
在 Node.js 里可以把全局保护做得轻一点。入口处先做基础配额和快速失败,避免请求继续深入业务层;同时把更细的判断交给接口和依赖层。这样即使全局阈值触发,也不会把所有业务语义都抹掉。
用户维度和接口维度要分开看
很多误伤来自把用户维度和接口维度混在一起。接口维度限流关注“这个接口整体能承受多少”,用户维度限流关注“某个用户或某个来源是否占用过多”。两者都需要,但不能互相替代。
比如登录发送验证码接口,接口整体承载 500 QPS 没问题,但同一个手机号一分钟请求十次就很可疑。这个场景要按手机号、设备、IP 或用户标识做限制。再比如商品详情接口,单个用户连续刷新几次可能是正常行为,但全站突然出现十倍流量,就应该从接口整体和缓存层面保护。
还有一类更细的维度是业务对象。某个活动 ID、商品 ID、门店 ID 被集中访问时,压力会落到同一批缓存 key 或数据库行上。如果只按用户限流,可能看不出热点对象已经把下游压满。活动类业务尤其要关注这一点,因为热点往往不是平均分布的。
一个比较稳的策略是从粗到细组合:全局阈值保护服务,接口阈值保护路径,用户或来源阈值防止滥用,对象阈值保护热点资源。组合不是越多越好,每加一层都要能解释它保护什么、触发后返回什么、如何观察误伤。
下游变慢时,限流要配合超时和熔断
只有限流,没有超时和熔断,系统仍然可能被拖住。假设 Node 服务调用一个外部风控接口,平时 80ms 返回,故障时变成 3 秒。即使入口请求量没有上升,等待中的请求也会堆起来,连接池和内存都会被占用。这个时候继续让所有请求进入风控调用,只会把慢依赖的问题扩大到整个服务。
限流在这里要和超时、熔断一起工作。超时负责告诉调用方“等到这里就不等了”,熔断负责在下游持续失败时短时间停止调用,限流负责限制进入这条依赖链路的请求量。三者目标不同,但经常需要一起设计。
关键是不要把熔断后的行为写得太随意。有些业务可以降级,比如推荐接口可以返回缓存内容;有些业务必须失败,比如支付确认不能凭默认值继续;有些业务可以排队,比如报表生成可以延后。Node 服务做保护时,不能只看技术上能不能降级,还要看业务上是否允许。
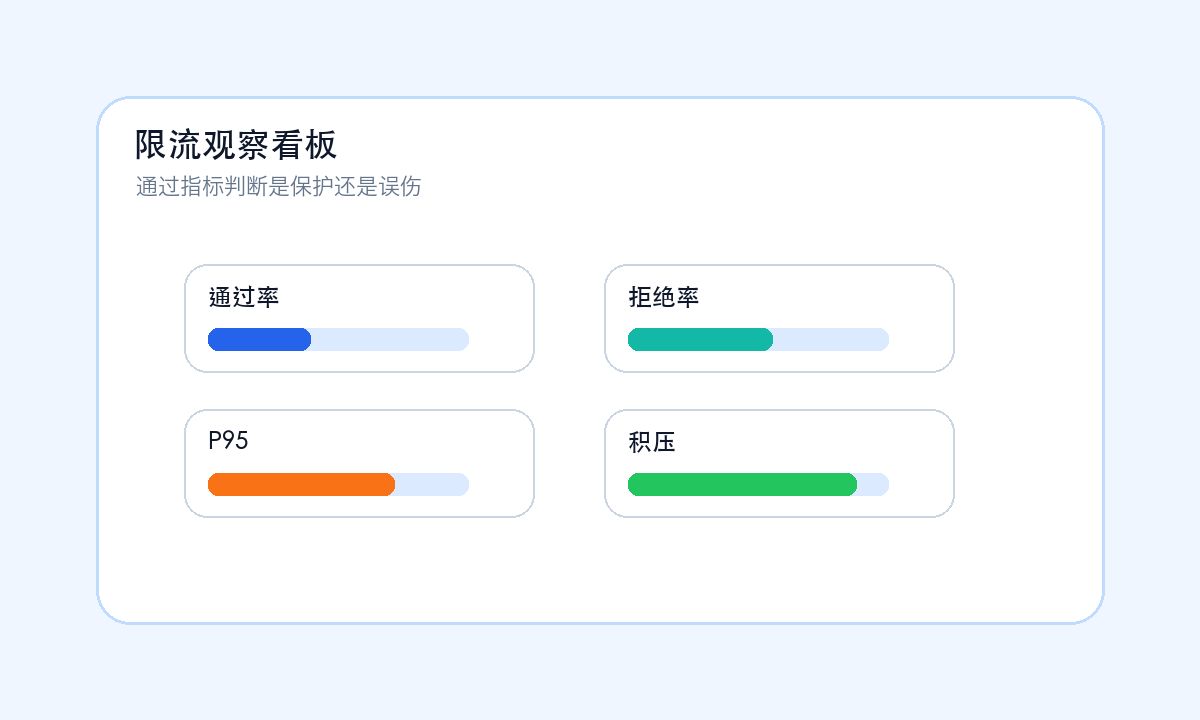
限流观察看板:通过率、拒绝率、P95 和积压要一起看。拒绝率升高不一定是坏事,但如果 P95 仍然上涨,说明保护位置可能不对。
返回“稍后再试”之前,先想用户下一步
限流触发后返回什么,也会影响业务体验。很多接口统一返回 429 或“稍后再试”,技术上没错,但用户不知道该等多久,也不知道重试是否会更糟。如果前端看到失败后立即自动重试,反而会制造更大的压力。
更好的做法是把限流结果设计成可消费的信息。比如返回明确的错误码、建议重试时间、是否允许前端展示排队状态、是否需要禁用按钮。对于用户主动操作,可以让前端给出短暂冷却;对于后台任务,可以转入队列;对于非核心展示接口,可以降级为缓存数据。
这里有一个取舍:信息越具体,前后端协作成本越高;信息越粗,用户体验和系统保护越难兼顾。关键路径值得做细一点,比如登录、支付、领取权益;普通展示路径可以简单一点,但也要避免前端盲目重试。
限流策略要能被观察和调参
一个上线后不可观察的限流策略,会让团队很焦虑。用户反馈被挡,研发不知道是不是阈值太低;系统变慢,业务不知道是不是限流没生效;压测通过,上线后又不知道真实流量和压测差在哪里。限流不是写完就结束,它需要指标和调参入口。
至少要记录几类指标:进入请求数、通过数、拒绝数、拒绝原因、命中维度、关键接口耗时、下游错误率。不要只记录总拒绝数,因为总数无法判断误伤来自哪个接口、哪个用户群、哪个活动对象。日志里也要带 request id 和限流规则名,方便排查单个用户反馈。
调参也要有边界。临时把阈值调高能缓解用户投诉,但可能把下游打穿;临时调低能保护系统,但会扩大误伤。最好在发布前定义几个档位:正常、活动、保护、紧急。每个档位对应哪些阈值、谁有权限切换、切换后观察哪些指标。这样现场不用边争论边改配置。
策略选择要看失败成本
限流方案没有绝对正确,只有适不适合当前失败成本。对于读接口,短暂返回缓存或降级内容通常可以接受;对于写接口,尤其是支付、库存、权限变更,宁可明确失败,也不要让状态进入不确定区。对于后台任务,排队比直接失败更友好;对于实时交互,排队太久又会让用户困惑。
可以把常见策略放进一个矩阵里看:用户维度适合防滥用,接口维度适合保护高成本路径,依赖维度适合隔离故障;固定窗口实现简单但边界抖动明显,滑动窗口更平滑但成本更高,令牌桶允许一定突发,漏桶更强调平滑输出。不要为了算法名字好听而使用它,要看它是否解释得清触发时机和失败行为。
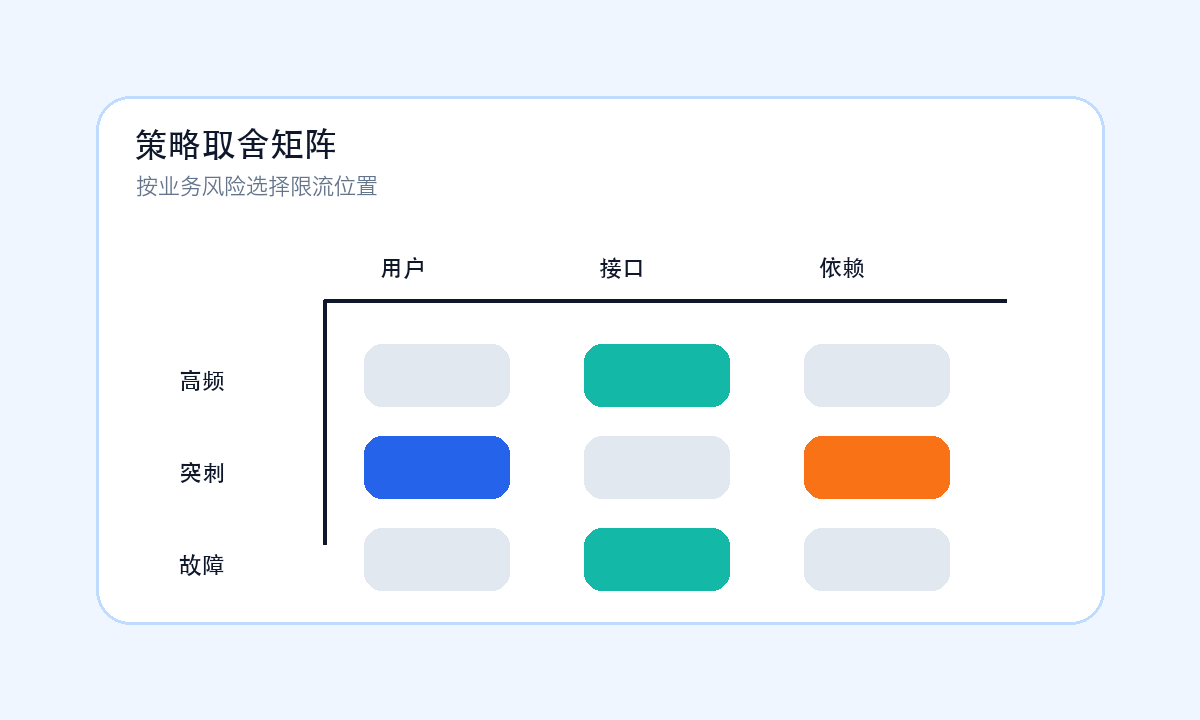
策略取舍矩阵:按用户、接口、依赖三个维度比较风险,能帮助团队决定限流先落在哪里。
一次比较稳的落地顺序
如果一个 Node 服务现在还没有系统限流,我不会建议一口气做成复杂平台。更稳的顺序是先找最容易造成事故的路径,做一层能观察、能回滚、能调参的保护,再逐步扩展。
可以按这个顺序推进:
列出核心接口和高成本接口,标明它们依赖哪些下游资源。
为服务入口加基础全局保护,避免极端突刺打穿进程。
给高成本接口设置独立阈值,不让它们挤占关键路径资源。
对验证码、登录、领取权益这类接口增加用户或对象维度限制。
为外部依赖配置超时、熔断和降级,不让慢依赖拖住整个服务。
接入通过率、拒绝率、耗时、积压和下游错误率等指标。
准备配置档位和回滚方案,避免线上临时改值没有边界。
这套顺序看起来不花哨,但它能让团队每一步都知道自己在保护什么。限流最怕的不是策略简单,而是策略说不清。说不清的限流,遇到投诉时没人敢调;遇到压力时也没人知道它有没有生效。
回到 Node 服务本身,限流不是性能优化的替代品。慢 SQL、缓存击穿、外部依赖超时、队列消费不足,这些问题仍然要修。限流只是让系统在问题出现时先稳住,不至于把局部故障扩散成全站不可用。真正成熟的做法,是把限流、超时、熔断、降级和观测放在一条链路里设计,而不是等接口被打挂以后再补一个阈值。